



统计模式识别是目前最成熟也是应用最广泛的方法。统计决策理论的基本思想是在不同的模式类中建立一个决策边界,利用决策函数把一个给定的模式归入相应的模式类中。统计模式识别的基本模型如图5-2,该模型主要包括两种操作模型:训练和分类。其中,训练主要通过对已有样本的大量统计分析,完成对决策边界的划分,并应采取一定的学习机制以保证基于样本的划分是最优的;而分类主要对输入的模式利用其特征和训练得来的决策函数而把模式划分到相应模式类中。
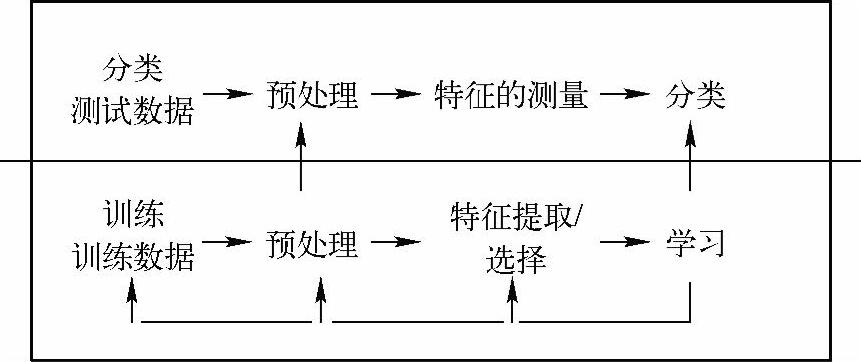
图5-2 统计模式识别模型
使用统计方法进行图像的模式识别时,特征提取占有十分重要的地位,因为训练和分类的对象往往不是图像本身,而是通过特征提取之后的数据,即将对象空间的数据通过特征提取映射到特征空间。但提取的方法并没有通用的理论指导,只能通过分析具体识别对象决定选取何种特征。特征提取后可进行分类,即从特征空间再映射到决策空间。为此需要引入鉴别函数,由特征向量计算出相应于各类别的鉴别函数值,通过鉴别函数值的比较实行分类。
统计模式识别根据采用方法的不同可以进行多种形式的分类:对条件密度已知的样本,可通过贝叶斯决策理论进行分类;对于条件密度未知的情况,可根据训练样本的类别是否已知将分类问题分为有监督学习和无监督学习两大类。其中,有监督学习和无监督学习又可根据是否通过参数决策分为参数估计和非参数估计。
统计模式识别的另一种分类方法是根据决策边界是否直接得到而将其分为几何分类法和概率分类法。几何分类经常直接从优化一定的代价函数构造决策边界;而概率分类法则基于概率密度,需要首先估计密度函数,然后构造分类函数指定决策边界。
下面简单介绍几种统计模式识别的方法。
1.几何分类法
几何分类法中,以模式存在的几何可分的特性作为分类依据,通过给定的判别函数进行分类。
(1)模板匹配法
它是模式识别中的一个最原始、最基本的方法,它将待识模式分别与各标准模板进行匹配,通过一个相关度函数计算待识模式的各个区域与各标准模板之间的相关度,每个位置都对应一个相关度值,该值越高,则匹配情况越好,最后取匹配最好的作为识别结果。需要说明的是,模板匹配对于像素十分敏感,目标的畸变、大小变化、角度变化都可能对结果产生较大影响。
(2)距离分类法
距离是一种重要的相似性度量,通常认为空间中两点距离越近,表示实际上两样本越相似。大约有十余种作为相似性度量的距离函数,其中使用最广泛的是欧氏距离。它是使用最为广泛的方法之一,常用的有平均样本法、平均距离法、最近邻法和K-近邻法。
(3)线性判别函数
和上述的方法不同,判决函数法是以判决边界的函数形式的假定为其特性的,而上述的方法都是以所考虑的分布的假定为其特性的。假如一个线性判决边界取成如式(5-1)的形式
g(x)=w1x1+w2x2+…+wdxd (5-1)
如果式(5-1)是合适的话,那么下一步就是要确定它的权系数。权系数可通过感知器算法或最小平方误差算法来实现。但作为一条规则,应用此方法必须注意两点:第一是方法的可适性问题,第二是应用判决函数后的误差准则。
(4)非线性判别函数
线性判决函数的特点是简单易行,但实际应用中许多问题实际是非线性的,对此,有两种处理方式:一种方法是将非线性函数转换为线性判决函数,又称为广义线性判决函数;另一种方法借助场的概念,引入非线性的势函数,它经过训练后即可用来解决模式的分类问题。
2.概率分类法
几何分类法是以模式类几何可分为前提条件的,但是模式的分布常常不是几何可分的,即在同一区域中可能出现不同的模式。这时,必须借助概率统计这一数学工具。可以说,概率分类法的基石是贝叶斯决策理论。
设有R类样本,分别为w1,w2,…,wR,若每类的先验概率为P(wii),i=1,2,3,…,R,对于一随机矢量X,每类的条件概率(又称类概率密度)为P(X/Wii),则根据贝叶斯公式,后验概率如式(5-2)所示:
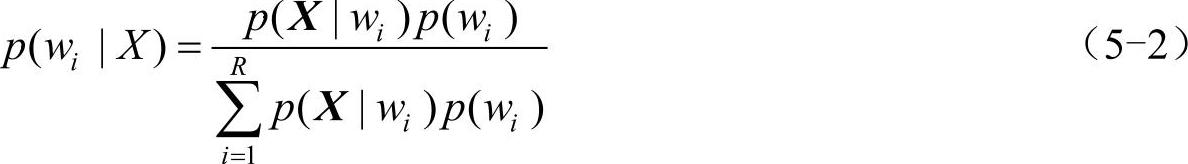
从后验概率出发,有贝叶斯法则:
若j=argmax[p(wi|X)],则X∈wj,其中i,j=1,2,…,R,且∀j≠i
(1)朴素贝叶斯分类器(NBC)
朴素贝叶斯分类是一种十分简单的分类算法,其基本思想为:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别,如我们看到一个黑人,一般会猜测他来自非洲,因为黑人中来自非洲的比例最高。在没有其他可用信息下,选择条件概率最大的类别,这就是朴素贝叶斯的基本思想。(https://www.xing528.com)
朴素贝叶斯分类的工作过程如下。
1)每个数据样本用一个n维特征向量X={x1,x2,…,xn}表示,分别描述对n个属性A1,A2,…,An样本的n个度量。
2)假定有m个类C1,C2,…,Cm。给定一个未知的数据样本X(即没有类标号),分类法将预测X属于具有最高后验概率(条件X下)的类。即朴素贝叶斯分类将未知的样本分配给类Ci,如式(5-3)所示。
P(Ci/X)>P(Cj/X),1≤j≤m,j≠i (5-3)
这样,最大化P(Ci/X)。其P(Ci/X)最大的类Ci称为最大后验假定。根据贝叶斯定理,有式(5-4)和式(5-5)
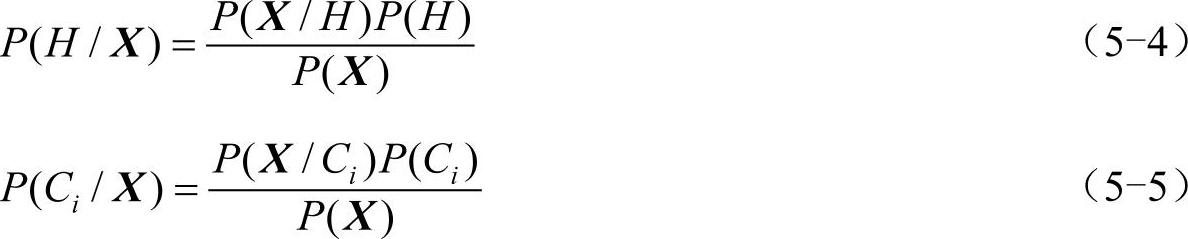
3)由于P(X)对于所有类为常数,只需要P(X/Ci)P(Ci)最大即可。如果类的先验概率未知,则通常假定这些类是等概率的,即P(C1)=P(C2)=…=P(Cm),并据此只对P(X/Ci)最大化。否则,最大化P(X/Ci)P(Ci)。注意,类的先验概率可以用P(Ci)=si/s计算,其中si是类Ci中的训练样本数,而s是训练样本总数。
4)给定具有许多属性的数据集,计算P(X/Ci)的开销可能非常大。为降低计算P(X/Ci)的开销,可以做类条件独立的朴素假定。给定样本的类标号,假定属性值相互条件独立,即在属性间,不存在依赖关系。这样

概率P(X1/Ci),P(X2/Ci),…,P(Xn/Ci)可以由训练样本估值,其中:
①如果Ak是分类属性,则p(Xk/Ci)=sik/si,其中sik是在属性Ak上具有值xk的类Ci的样本数,而si是Ci中的训练样本数。
②如果Ak是连续值属性,则通常假定该属性服从高斯分布,因而
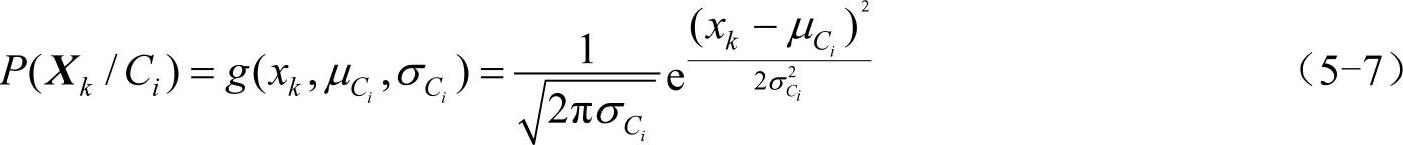
其中,给定类Ci的训练样本属性Ak的值,g(xk,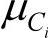 ,
,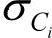 )是属性Ak的高斯密度函数,而
)是属性Ak的高斯密度函数,而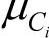 ,
,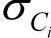 分别为平均值和标准差。
分别为平均值和标准差。
5)为对未知样本X分类,对每个类Ci,计算P(X/Ci)P(Ci)。样本X被指派到类Ci,当且仅当
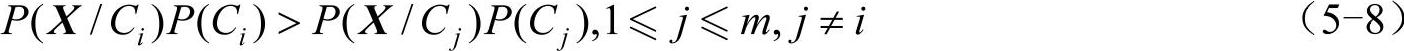
换言之,X被指派到其P(X/Ci)P(Ci)最大的类Ci。
整个朴素贝叶斯分类分为如下三个阶段。
第一阶段——准备工作阶段。这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后对一部分待分类项进行人工分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并记录结果。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
(2)半朴素贝叶斯分类模型(SNBC)
为了进一步提高分类性能,有人提出了半朴素贝叶斯分类的构想。半朴素贝叶斯分类模型对朴素贝叶斯分类模型的结构进行了扩展,其目的是为了突破朴素贝叶斯分类模型特征属性间独立性假设限制。目前,半朴素贝叶斯分类模型学习的关键是如何有效组合特征属性。半朴素贝叶斯分类学习算法可以解决目前一些学习算法中存在的效率不高及部分组合意义不大的问题。SNBC的结构比NBC紧凑,在SNBC的模型构建过程中,依照一定的标准将关联程度较大的基本属性(即NBC中的特征属性)合并在一起构成“组合属性”(也称之为“大属性”),因而如何有效组合特征属性是SNBC学习的关键。逻辑上,SNBC中的组合属性与NBC中的基本属性没有根本性差别,SNBC的各个组合属性之间也是相对于类别属性相互独立的。图5-3是SNBC的模型示意图。
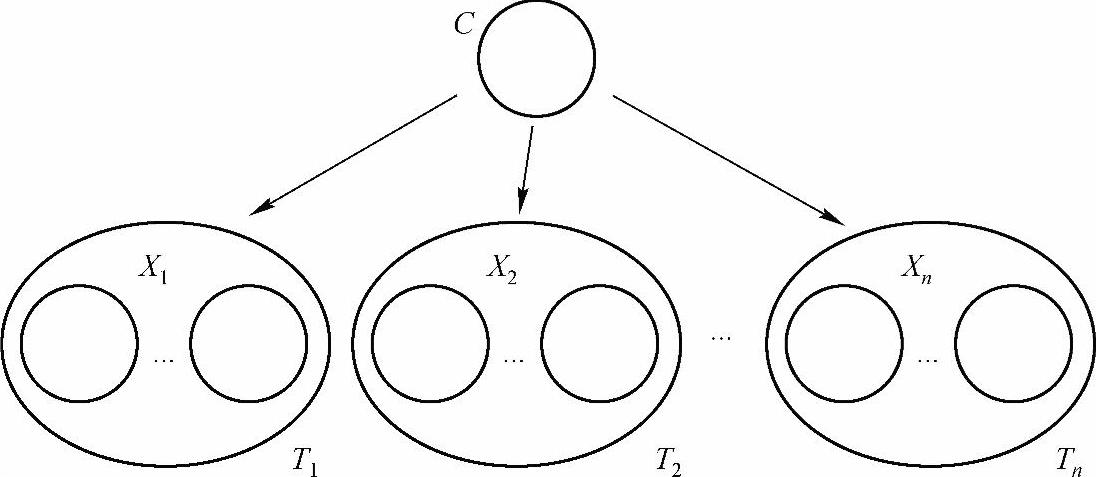
图5-3 半朴素贝叶斯分类结构示意图
这类模型通过将依赖性强的基本属性结合在一起构建新的模型,这样可以部分屏蔽NBC中独立性假设对分类的负面作用。但从名称可以看出,SNBC依然属于朴素贝叶斯分类的范畴。这是因为除了结构上的差别之外,计算推导过程与NBC无异。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。