



假定中继需要支持上下行传输,虽然UMTS的上下行链路帧结构和编码方式都不同,但是其复杂度的数量级是相同的。为了简单化,假定上下行链路需要相同的内存量、运算量和Load/Store操作次数,我们对上一节提出的4种UMTS中继场景进行复杂度和功耗的定量分析。
5.5.4.1 辅助性AF协议的模拟硬件实现
辅助性AF协议采用模拟硬件实现时需要保证两个FDD链路(在4个频段上),在5.2.1中解释过,其原因是目前采用FDR协议的中继都比采用TDR协议的中继设备尺寸小并且简单。因此复杂性和功耗的分析如下:
●运算复杂度。辅助中继采用模拟硬件实现时没有运算复杂性和Load/Store操作,即
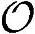 =0,
=0,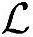 =0,
=0,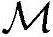 =0。
=0。
●功耗。没有运算复杂度,与之相应的功耗也因此为0。对于射频前端,忽略了频率转换带来的功耗,总的功耗是表5.7给出的值的2倍,这是因为需要维持两个FDD链路。对于这种类型的AF中继,一般都有稳压电源供电,总的功耗估计为P=2×763mW=1.53W。
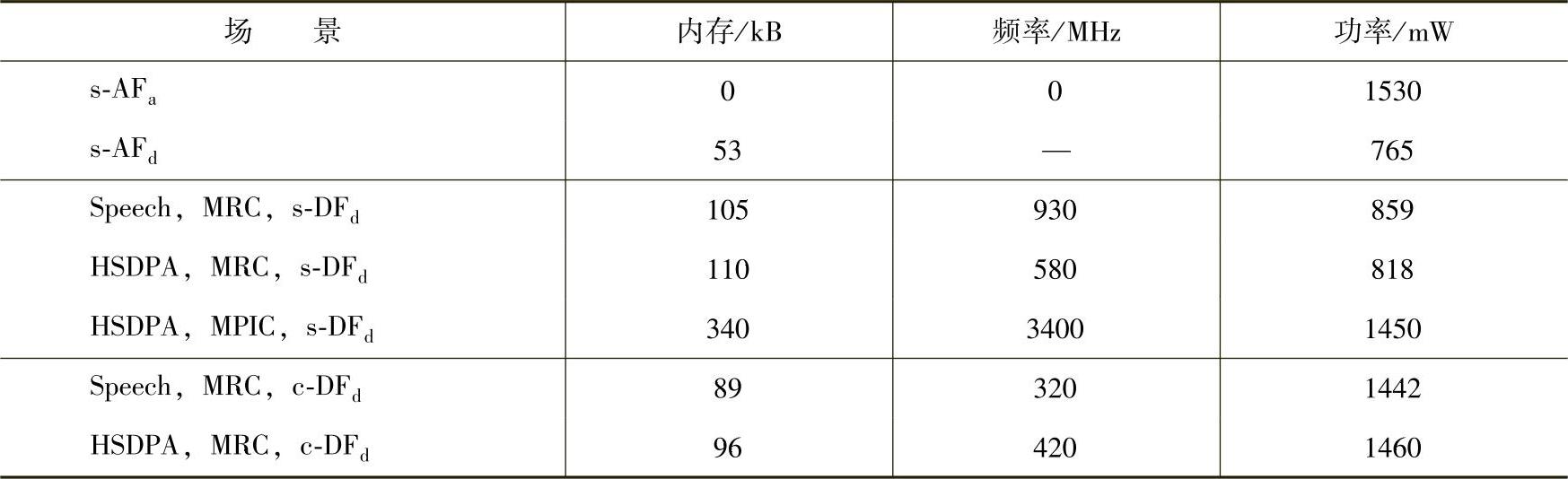
●重要影响因素。功耗和复杂度是与中继的业务数量和类型无关的,但会根据FDD连接数的增加而成倍增加。天线数的增加会给接收端带来噪声增益,同时给发射端带来波束赋型增益,但是由于前一种增益很小,而后一种情况很难实现,所以实际中用处不大。但是另外一方面,天线数的增加会带来功耗的约成倍的增加。表5.9给出了不同场景下的结果总结和比较。
表5.9 UMTS场景下中继的主要需求总结
5.5.4.2 辅助性AF协议的数字硬件实现
辅助性AF中继采用数字硬件实现的话可以使用TDR协议。不考虑频谱有效性的话,可假定只有一个FDD链路作为上下行中继传输。这种中继也不需要考虑加法和乘法的运算复杂度,但是需要考虑对过采样数据的Load/Store操作以及内存容量。典型地,模拟数据一般需要以两倍带宽的速率进行采样,因此采样速率SR至少应该是10MHz。相当于信号处理过程中过采样因子OSF=2,当然更多情况下采用更高的采样因子。复杂性和功耗因此为:
●运算复杂度。运算复杂度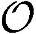 =0;中继的接收端每时隙中Store操作次数为10×106样值/s×10×10-3s/帧÷15时隙数/帧≈6.7×103采样值/时隙,在发送端Load操作的次数也与之相同。因此每个时隙总共需要Load/Store操作次数为
=0;中继的接收端每时隙中Store操作次数为10×106样值/s×10×10-3s/帧÷15时隙数/帧≈6.7×103采样值/时隙,在发送端Load操作的次数也与之相同。因此每个时隙总共需要Load/Store操作次数为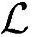 =13.3×103。上下行传输总的内存需要为
=13.3×103。上下行传输总的内存需要为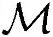 =4kB/样值×13.3·103样值/时隙=53.2kB/时隙。
=4kB/样值×13.3·103样值/时隙=53.2kB/时隙。
●功耗。采用5.5.3节的方法,由Load/Store操作带来的功耗计算为2.2mW。射频前端假定采用非电池供电的话功耗约为763mW(取自表5.7)明显大于Load/Store操作的功耗。总功耗因此为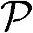 =765mW。
=765mW。
●重要影响因素。功耗和复杂度是与中继的业务数量和类型无关的。Load/Store操作数和内存需求会随着采样率的增加而成倍增加,同时功耗也会根据FDD连接数的增加而成倍增加。增加天线带来的影响和模拟硬件场景中是相同的。表5.9对上述结果进行了总结,并与其他场景进行了比较。
5.5.4.3 辅助性DF协议的数字硬件实现
辅助性DF中继采用数字硬件结构实现时,可以采用任何形式的接入、复用和中继协议。因此,我们假定采用TDR中继协议,并且只使用一条FDD链路支持上下行传输。上一节讨论过,辅助性DF基于数字硬件结构实现时并不会增加运算的复杂性。复杂度主要受系统参数和UMTS业务参数的影响,在这里我们将要研究语音和HSDPA数据业务。对于一般性的系统参数,我们假定如下:信道时延扩展DS=12;Nchips=2560;匹配滤波器长度LRCC=8;导频的比特数Nbit,pilot=20;导频的符号数Npilot=256;导频的扩频因子SFpilot=256;导频的码片数Nchip,pilot=2560;Rake指峰数L=4;全信道捕获和部分信道捕获占用比Racq=0.9;一般设备生产商会以码片速率的两倍进行接收数据采样,因此OSF=2,接下来为了跟踪信道的时延进行8样值/码片的插值处理。
对于12.2kbit/s的语音业务,我们假定:QPSK调制,每时隙的数据符号个数为Ndata=20;扩频因子SFdata=128;多码个数MC=1;卷积码码率Rc=1/3;DTCH的删余度为Rp,dtch=0.2;DCCH的删余度为Rp,dcch=0.2;解信道映射前比特数为Nrx≈840;传输块的大小为Ndata=840/3;我们同时假定在有限的热点覆盖地区中继需要支持U=40个话音用户。另外,只考虑MRC检测器。接下来,对于支持UMTS话音用户的中继进行复杂度和功耗的定量分析:
●运算复杂度。参考图5.6,接收机的复杂度包括:RRC滤波器+信道捕获+U×其余5.5.2节中所述的模块的复杂度。中继发射机的复杂度为:U×外部Modem(用编码器来代替卷积译码器的复杂度)+U×扩频操作+RRC滤波。将上述参数放到5.5.2节中的复杂度表达式中,可以得到每个时隙内总的运算次数 ≈2500000,Load/Store操作次数
≈2500000,Load/Store操作次数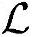 ≈594000,所需内存为
≈594000,所需内存为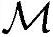 ≈105000字节,这里我们只简单将各个模块所需内存相加。为了得到中继的处理频率
≈105000字节,这里我们只简单将各个模块所需内存相加。为了得到中继的处理频率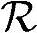 ,需要将上面获得的
,需要将上面获得的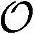 除以4(每个时钟周期内指令数),再除以时隙的长度(10ms/15),得到
除以4(每个时钟周期内指令数),再除以时隙的长度(10ms/15),得到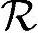 ≈930MHz,参照表5.8可知当前或以后的4ALUDSP皆可满足要求。
≈930MHz,参照表5.8可知当前或以后的4ALUDSP皆可满足要求。
●功耗。利用上述参数以及5.5.3节的方法,可知由Load/Store操作带来的功耗为96mW。射频前端功耗参考自表5.7,当采用非电池供电时约为763mW。总功耗为P=859mW。
●重要影响因素。如果语音用户数增加一倍,则处理器频率需相应地增加1.5倍,总功耗增加约5%。如果RRC滤波器长度增加一倍,则处理器频率需增加25%,功耗没有影响。同样地,如果FDD链路数增加一倍,则所有功耗也成倍增加。对于天线增加带来的功耗在前面并未详细分析,但一般会带来处理器频率成倍增加和额外10%功耗的需求。(https://www.xing528.com)
对于速率约为1.5Mbit/s的HSDPA数据业务来说,假定如下条件:16QAM调制,每时隙的数据符号个数为Ndata=160;扩频因子SFdata=16;多码个数MC=5;卷积码码率Rc=1/3;Turbo码译码迭代次数为Niter=4;MPIC每级迭代次数R=1;MPIC级数为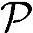 =4;DTCH的删余度为Rp,dtch=0;DCCH的删余度为Rp,dcch=1;解信道映射前比特数为Nrx≈2×960×MC;传输块的大小为Ndata=2×960×MC/3;我们同时假定中继只需要支持U=1个HSDPA数据用户,这相当于前面场景中使用码字总数。另外,MRC和MPIC检测器都考虑使用。接下来,对于支持HSDPA业务的中继进行复杂度和功耗的定量分析:
=4;DTCH的删余度为Rp,dtch=0;DCCH的删余度为Rp,dcch=1;解信道映射前比特数为Nrx≈2×960×MC;传输块的大小为Ndata=2×960×MC/3;我们同时假定中继只需要支持U=1个HSDPA数据用户,这相当于前面场景中使用码字总数。另外,MRC和MPIC检测器都考虑使用。接下来,对于支持HSDPA业务的中继进行复杂度和功耗的定量分析:
●运算复杂度。根据上述场景中对于话音业务同样的分析方法,每个时隙总的运算操作次数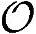 =1600000,Load/Store操作次数
=1600000,Load/Store操作次数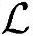 ≈340000,所需内存
≈340000,所需内存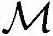 ≈1100000B。处理频率
≈1100000B。处理频率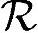 ≈580MHz。
≈580MHz。
●功耗。利用上述参数以及5.5.3节的方法,可知由Load/Store操作带来的功耗为55mW。射频前端功耗可参考表5.7,当采用非电池供电时约为763mW。总功耗为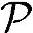 =818mW。很明显,相比话音业务来说,Load/Store消耗的功率提高了,增加的部分约占总功率的7%。
=818mW。很明显,相比话音业务来说,Load/Store消耗的功率提高了,增加的部分约占总功率的7%。
●重要影响因素。如果HSDPA用户数或者多码数增加一倍的话,需要处理器频率增加1.5倍,总功耗增加约5%。调制方式如果由16QAM变为QPSK的话,处理器频率需求降低20%,功耗降低3%。Turbo码译码迭代次数增加一倍,这和增加RRC滤波器长度在复杂度方面的影响一致。同样地,如果FDD链路数增加一倍的话,所有功耗也成倍增加。天线数的增加需要处理器频率以相应比例增加,但是对于功耗没有太大影响。
对于基于MPIC检测器的UMTSHSDPA业务中继来说,对复杂度和功耗的分析如下:
●运算复杂度。根据上述场景中对于话音业务同样的分析方法,每个时隙总的运算操作次数 =9000000,Load/Store操作次数
=9000000,Load/Store操作次数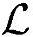 ≈4200000,所需内存
≈4200000,所需内存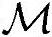 ≈340000B。处理频率
≈340000B。处理频率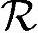 ≈3400MHz。MPIC检测器显然是非常复杂的,相比MRC检测器来说,需要性能更高的数字硬件结构来支持。
≈3400MHz。MPIC检测器显然是非常复杂的,相比MRC检测器来说,需要性能更高的数字硬件结构来支持。
●功耗。由Load/Store操作带来的功耗为686mW。射频前端功耗可参考表5.7,当采用非电池供电时约为763mW,总功耗为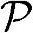 =1450mW,数字处理和射频前端消耗功率基本相等。
=1450mW,数字处理和射频前端消耗功率基本相等。
●重要影响因素。如果HSDPA用户数或者多码数增加一倍的话,则处理器频率和总功耗需增加约1.3。如果调制方式由16QAM变为QPSK的话,则处理器频率需求降低12%,功耗降低5%。Turbo码译码迭代次数的增加对于复杂度基本没有影响,RRC滤波器长度的增加使得处理器频率成约1.5倍的增长,功耗方面没有影响。增加MPIC级数对于复杂度和功耗都是相应成倍增加,增加MPIC每级的迭代次数一倍需要处理器频率增加33%,功耗增加约20%。同样地,如果FDD链路数增加一倍的话,所有功耗也成倍增加。天线数的增加需要处理器频率相应比例增加,功耗增加约15%。
在表5.9中对上述结果进行了总结和比较。
5.5.4.4 协同DF的数字硬件结构实现
辅助DF中继一般作用类似于基站,而协同DF中继是典型的移动终端,需要传输自身的数据。因此需要尽量降低由中继带来的复杂性,这也是为什么除了中继终端自身的话音和HSDPA业务外,只考虑协同传输一个话音和一个HSDPA数据连接。上一节分析表明MPIC检测器具有很高的复杂度,因此这里只考虑使用MRC检测器。对于HSDPA,我们假定使用16QAM但不用多码传输,这样每个用户的有效数据速率约为320kbit/s。
只支持一个中继UMTS话音业务的协同中继的复杂度和功耗分析如下:
●运算复杂度。根据上述同样的分析方法,每个时隙总的运算操作次数 =8500000,Load/Store操作次数
=8500000,Load/Store操作次数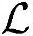 ≈72000,所需内存
≈72000,所需内存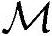 ≈89000B。处理频率
≈89000B。处理频率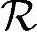 ≈320MHz。协同中继对于转发话音业务还是比较轻松的。
≈320MHz。协同中继对于转发话音业务还是比较轻松的。
●功耗。由Load/Store操作带来的功耗为12mW。射频前端功耗可参考表5.7,当采用电池供电时约为830mW。因为中继本身就是一个终端,高层协议处理和外围硬件的功耗为600mW。总功耗为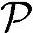 =1442mW。
=1442mW。
●重要影响因素。每增加一个需要中继的语音用户,处理器频率需增加约5%,但功耗的增加几乎可以忽略。RRC滤波器长度的增加要求处理器频率增加约25%,功耗方面没有影响。FDD链路数增加一倍的话,功耗增加约40%~50%。最后,天线数的增加需要处理器频率按比例增加,功耗方面没有影响。只支持自身业务和一个中继UMTSHSDPA业务的协同中继的复杂度和功耗分析如下:
●运算复杂度。根据上述同样的分析方法,每个时隙总运算操作次数 =1100000,Load/Store操作次数
=1100000,Load/Store操作次数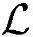 ≈180000,所需内存
≈180000,所需内存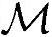 ≈96000B。处理频率
≈96000B。处理频率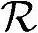 ≈420MHz。协同中继因此可以支持转发这个HSDPA连接。
≈420MHz。协同中继因此可以支持转发这个HSDPA连接。
●功耗。由Load/Store操作带来的功耗为30mW。射频前端功耗可参考表5.7,当采用电池供电时约为830mW。高层协议处理和外围硬件的功耗为600mW。总功耗为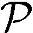 =1460mW。
=1460mW。
●重要影响因素。影响因素和程度和上述基于MRC的辅助中继来转发HSDPA业务的场景。除了协同中继场景下,需要额外消耗600mW的高层协议和外围硬件功耗。
在表5.9中对上述结果进行了总结和比较。可以发现在各种场景下,内存都不是一个制约性的因素,一方面是因为信号处理不需要太多的内存,另一方面是因为内存价格较为低廉。而对于处理器频率方面,4ALU的DSP(或相同级别)就可以满足系统需求。但如果采用MPIC检测器,将需要较高的处理器频率,因此从性能方面也不推荐使用该方法。最后要指出的是,模拟中继的功耗是非常高的,甚至超过复杂的数字结构中继,这是因为具有放大器的射频链路至今仍是最耗能的模块。协同中继的功耗较高的原因,是因为一部分功率消耗在高层协议和外围器件上。对于中继天线而言,目前的技术趋势是将中继的天线数翻倍,这会带来处理器频率需求也近似成倍增长,但天线数的增加对于功耗的影响是很小的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。