



数据分发用于处理传感器到汇聚节点的数据通信。我们将从数据源到汇聚节点的数据流称为下行流,反方向称为上行流。数据分发的核心问题是指向汇聚节点的路由问题。针对包含静态汇聚节点的WSN,人们开发了许多路由协议。在汇聚节点移动的场景中,数据分发是一个位置服务(见第8章)和路由(见第4章)的联合问题,其中节点共享多个共同目标(即汇聚节点)。
最近,参考文献(Wu and Chen,2007)研究了网络范围内基于洪泛的汇聚节点位置更新的偏移和汇聚节点移动性节能问题,并提出了一种双汇聚节点方案。在该方案中移动汇聚节点通过采用范围受控的洪泛来更新其位置,实现节能的目标;没有移动汇聚节点最新位置的传感器向可选已知静态汇聚节点发送数据。该方案没有解决指向移动汇聚节点的路由实际问题。文献提出了经过特殊修正的基于非洪泛的解决方案。下面,我们对与该主题有关的一些典型相关工作进行综述。
1.基于树的方法
参考文献(Kim et al.,2003)提出了一种可扩展节能异步分发(Scalable En-ergy-efficient Asynchronous Dissemination,SEAD)协议。针对每个数据源,SEAD构建了一棵类似SMT的数据分发树,称为d-tree,树根节点为数据源。最初,d-tree中仅包含其根节点。每个汇聚节点选择最近的邻近传感器作为接入节点。当它准备接收来自于源的数据时,它通过其接入节点加入该数据源的d-tree。在d-tree中,树叶是汇聚节点接入节点,内部节点为添加的Steiner节点,称为复制节点。图6-9给出了数据源B的d-tree。
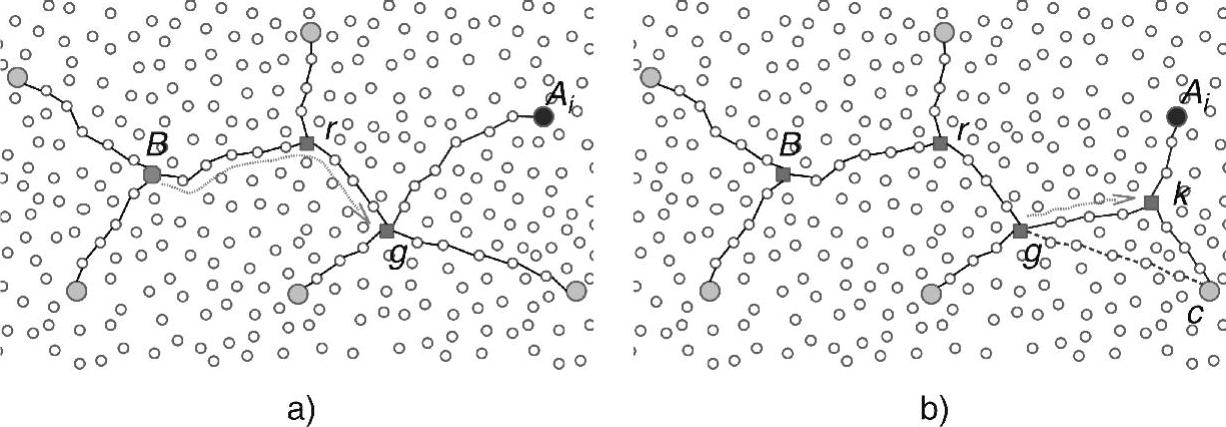
图6-9 SEAD
a)非复制模式 b)连接复制模式
当汇聚节点Si准备加入源B的d-tree时,它直接(不通过d-tree)通过其接入节点Ai,采用基本路由协议,向B发送一条加入请求。请求消息包含了Ai的位置信息和Si中的预期数据速率Ri。当B接收到该消息后,它启动一个迭代搜索阶段,来寻找门副本。这是一个复制节点,通过该节点,Ai可以连接到d-tree上。针对每个受访树节点r的节能测试结果,搜索过程从B开始,沿着d-tree下行方向前进。我们用K(r)表示连接Ai和节点r的额外功耗。在能量测试中,节点r为每个树的子节点计算F=K(r)-K(h)。如果所有结果小于0,则通过能量测试,且r成为门副本;否则,则节点r将消息转发给能够实现F最大化的子节点。如果没有节点满足条件,则搜索最终到达一个树叶节点。在这种情况下,树叶节点的父节点作为门副本。图6-9说明了搜索阶段,它在节点g处停止。
我们现在研究Ai如何连接到发现的门副本g。有两种可能的连接模式,如图6-9所示。在非复制模式中,Ai作为子节点连接到g。在连接复制模式中,首先生成一个作为g子节点的新复制节点k,删除g及其子节点c之间的树链路,然后Ai和c连接到新复制节点k上。通过局部计算,门副本g选择能够实现d-tree树上g附近能耗较小的连接模式。当采用连接复制模式时,也是通过计算确定能够一起生成新复制节点的子节点c和邻居r。在这种情况下,g向r发送一条包含深度计算需要的所有必要信息。当接收到该信息后,节点r重复与c及其邻居集有关的上述过程。复制节点选择时所在的节点k成为新的复制节点,Ai与k建立连接,c成为其兄弟。如果有必要,门副本g通知其父节点,将数据速率提高到Ri。
当汇聚节点Si移动时,如果Si及其接入节点Ai之间的跳数超过阈值Hi时,它使用当前最近的邻居——新节点A′i来代替其接入节点。如果AiA′i小于阈值Tm,则不需要改变d-tree结构,即可将Ai与A′i连接起来。否则,Ai通过A′i将最新的位置信息发送给B,然后B触发复制搜索阶段来更新d-tree。我们可以看出SEAD算法的性能,与Tm的选择有很大关系。如果Tm太大,则数据分发路径的最优性降低;如果Tm太小,则d-tree的维护开销将会很高。在汇聚节点移动性无法预测或汇聚节点随机移动的情形中,提前选择恰当的Tm值是非常难的。
2.强制学习法
参考文献(Baruah et al.,2004)提出了一种针对移动汇聚节点数据分发的强制学习时域混合路由(Hybrid Learning-enforced Time Domain Routing,HLETDR)算法。汇聚节点沿着某一固定模式移动。汇聚节点访问路径定义为最短持续时间,经过该持续时间后,汇聚节点移动模式再次重复。每个节点将汇聚节点访问路径平均分为预定数目的时域,并为每个时域内它的所有邻居分配一个权重。权重表示在特定时间,向汇聚节点转发数据包的最佳路径。最初,邻居的权重相同,这表明它们的数据分发性能一样好。目标是在不同时域内,寻找从每个传感器到汇聚节点的最佳路由路径。这可以通过在学习过程中合理调整传感器邻居的权重来实现,正面我们将进行解释。
节点附近定期被汇聚节点访问的节点称为痣。图6-10给出了汇聚节点路径上的3个痣。每个数据源自发将数据通过多跳消息中继,推送给汇聚节点。每个中间节点将数据包给具有最高权重的邻居。网络可能会同时传输数据包的多个拷贝。所有这些拷贝最后将到达一个痣,并在该痣处进行缓存。当汇聚节点访问该痣时,它
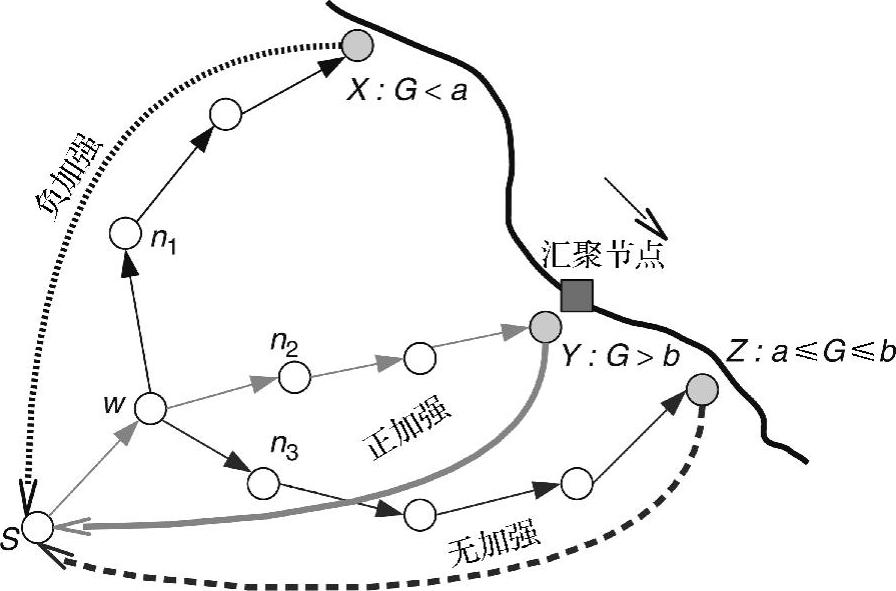
图6-10 HLETDR(https://www.xing528.com)
可以从该痣处获取数据。例如,在图6-10中,当汇聚节点从北向南沿着指示轨迹移动时,数据包的3个拷贝,在特定时域,沿着指向汇聚节点的3条路径从数据源S开始传输,它们分别到达痣X、Y和Z。
每个痣学习汇聚节点随时间的运动规律,并采用高斯分布函数以统计方式描述汇聚节点在汇聚节点访问路径内的到达时间。这样,在任意时域内,能够估计汇聚节点位于每个痣附近区域的可能性,并当痣在特定时间接收到数据时,评估数据传输路径优度G。如果数据到达时间接近汇聚节点到达时间的平均值,则G值较高,否则G值较低。例如,在图6-10中,由3个痣X、Y和Z计算的G值比较起来,相对值分别为低、高、中。需要注意的是,如果某个痣没有足够的存储空间来存储预期流量,或者移动规模变化幅度非常大,或者针对传输的特定时间约束条件需要满足,则执行痣到痣沿着汇聚节点路径的数据传输,直至到达包含一个汇聚节点的RP。
计算出数据传输路径的优度G后,痣沿着反向路由,向数据源发送G值。在路径中,基于G值和两个预定义的阈值a和b,每个中间节点w为其下一跳(即指向汇聚节点的下行流邻居)更新权重。如果0<G<a,则降低n的权重,这称为负加强,意味着m不是当前时域内指向汇聚节点的理想下一跳节点。如果a≤G≤b,则n的权重保持不变,这称为无加强。如果b<G<1,则提高n的权重,这称为正加强,意味着在当前时域内,n位于一条指向汇聚节点的理想路径上。图6-10中,痣X、Y、Z在当前时域内,分别启动负加强、正加强和无加强。通过这些方法,节点w能够局部选择与时域有关的、用于在未来及时传输数据的最佳路径。
3.请求区方法
参考文献(Ammari and Das,2005)提出了一种加权熵数据分发(Weighted En-tropy Data dissemination,WEDAS)方案。该方案是请求区位置服务(见第8章)的一个变形。它隐含地假设传感器的传输半径受限可调,并采用额外功率感知下一跳节点选择方法,来实现指向移动汇聚节点的路由。该方案的创新之处在于对节点剩余能量不确定性进行了量化。下面,我们详细介绍该方案,并讨论可能的改进方案。
假设汇聚节点S当前位于位置a1,将要移动到位置a2。S的相对移动区Zm(D)定义为直径为|a1a2|的圆形区域。在离开a1之前,S通过洪泛整个网络,将Zm(D)以及两条位置信息a1和a2作为广告消息发送给网络中的所有节点。在S移动期间,S不再发送任何广告消息。
每个传感器si根据接收到的汇聚节点广告消息来计算Zm(D),并识别邻居的一个子集CNS(si),称为协调节点集(Coordinator Node Set,CNS)。CNS是由存在于区域(即请求区位置服务中的请求区)的、由其通信范围和两个线段sia1和sia2定义的节点构成的。该集合中的节点都是移动汇聚节点方向上si的所有邻居。当向S发送消息时,si将这些消息通过集合中的某个节点,路由到Zm(D)的中心c。
传感器si为CNS(si)中的每个节点sj维护两个矢量。一个矢量包含sj在k个不同时刻的剩余能量精确值,它由sj以广告形式发送出去;另一个矢量包含sj在这些时刻的剩余能量估计值。两个矢量之间的相对能量距离是所有对应矢量元素对之间的距离绝对值的平均值。在时刻tk+1处sj的剩余能量估计值,是它在tk处sj的剩余能量精确值减去相对能量距离。
传感器节点sj被si选为指向S的路由下一跳的概率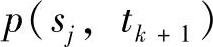 ,定义为sj的剩余能量估计值与CNS(si)中所有节点的剩余能量估计值和之比。与S有关的sj和si之间的三角距离为
,定义为sj的剩余能量估计值与CNS(si)中所有节点的剩余能量估计值和之比。与S有关的sj和si之间的三角距离为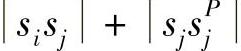 ,其中
,其中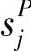 是sj在线段sic上的垂直投影,如图6-11所示。为sj分配一个权重
是sj在线段sic上的垂直投影,如图6-11所示。为sj分配一个权重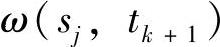 ,它是sj的三角距离与CNS(si)中所有节点的三角距离和之比。
,它是sj的三角距离与CNS(si)中所有节点的三角距离和之比。
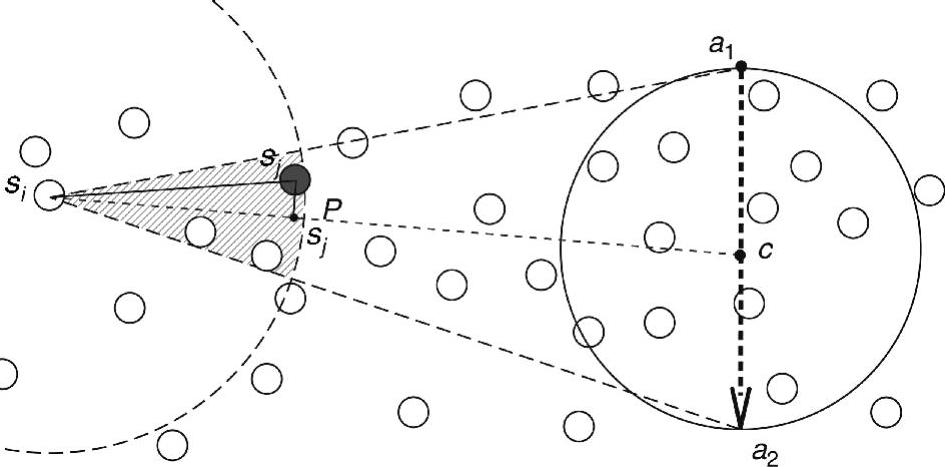
图6-11 WEDAS
sj的加权熵定义为H(sj,si,tk+1)=-ω(sj,tk+1)p(sj,tk+1)lgp(sj,tk+1)。它可用于测量sj剩余能量的不确定性。用于将消息路由到S的si的下一跳将是具有最小加权熵的sj。换句话说,协议支持同时更靠近si和直线sic的sj(这样它成为定向路由的一个变形)。|sisj|最小化会降低si的传输能耗;另一方面,距离sjsjP最小化能够实现路由路径最小化。
WEDAS有两个主要缺点。当使用能量充足的节点时,WEDAS的目标是寻找具有最大跳数的直线路径。在节能方面,仅当公式(6-1)中假设c=0时有效,但在实践中,这是不可能的。此外,WEDAS路由误差较高。原因是双重的。首先,路由目标不是预期汇聚节点位置,但通常是相对移动区的中心。其次,跳选择来自于受到狭义地理区限制的CNS。当空穴区存在时,该集合可能是空集,因而会导致路由失败。
参考文献(Li and Stojmenovic,2008)提出了一种局部数据分发算法,它在上述两方面对WEDAS进行了改进。在该算法中,汇聚节点在以广告形式发送相对移动区信息时,将其移动速率信息分发给所有传感器。使用这种额外的速率信息,每个传感器能够在给定时刻,估计汇聚节点的位置,然后将消息路由到汇聚节点。为了提高成功率,采用贪婪路由算法,而不是定向路由算法,将候选协调集扩展到包含那些可能是汇聚节点最佳位置的节点。更特殊的情况是,针对源到汇聚节点的数据分发,采用参考文献(Stojmenovic et al.,2003)中提出的请求区路由版。第8章将对请求区路由版进行详细讨论。加权熵的概念主要适用于节能跳选择。熵不是能量距离来衡量的,而是由成本进度比的倒数来衡量的(Stojmenovic,2006)。也就是说,对于时刻tk+1的节点sj来说,ω(sj,tk+1)=(siSk+1-sjSk+1)/sisj,其中si为当前节点,Sk+1为时刻tk+1的汇聚节点位置估计值。采用这种加权熵的新定义,算法支持跳选择中能量充足的节点,这会导致汇聚节点进度变大,传输距离变小。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。