



编译器支持几种存储模型,见表2-3。提供了命令行选项来根据所使用的特定dsPIC器件和存储器类型,选择最佳的存储模型。
表2-3 存储模型命令行选项
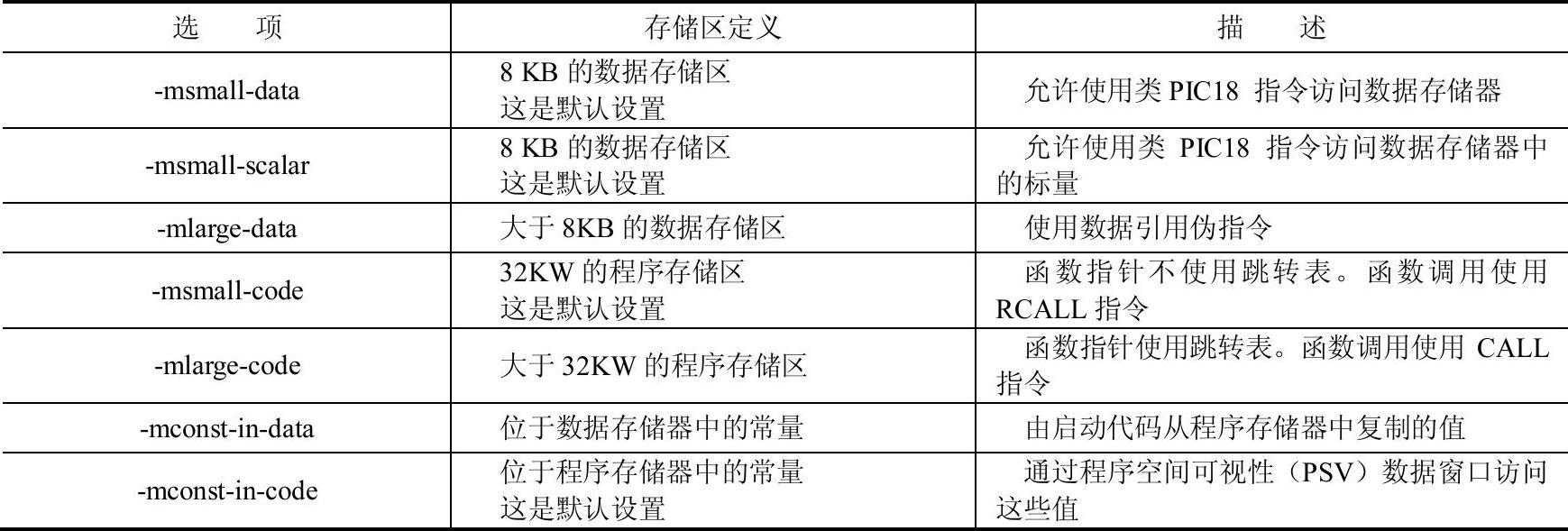
命令行选项适用于所有被编译的模块。各个变量和函数可以声明为near或far,以便更好地控制代码的生成。
1.near数据和far数据
如果变量分配到near数据段中,通常编译器能生成更好(更紧凑)的代码。如果一个应用的所有变量能存放在8KB的near数据存储区中,那么编译器在编译每个模块时就会被要求使用默认的-msmall-data命令行选项来将这些变量存放在near数据存储区中。如果标量类型(非数组或结构类型)所占用的数据总量小于8KB,可使用默认的-msmall-scalar选项。这要求编译器仅将应用中的标量存放在near数据段中。
如果这些全局选项都不适合,那么就使用下面的可选方案:
1)可以使用-mlarge-data或-mlarge-scalar命令行选项编译应用的某些模块。在这种情况下,仅这些模块使用的变量被分配到far数据段中。如果使用这个可选方案,在使用外部定义的变量时一定要小心。如果使用这两个命令行选项之一编译的模块使用了一个外部定义的变量,则定义这个变量的模块也要使用相同的选项编译,或者在变量声明和定义时指定far属性。
2)如果使用了-mlarge-data或-mlarge-scalar命令行选项,那么可通过指定near属性将变量排除在far数据空间外(即存放在near数据空间)。
3)命令行选项的作用域仅限于模块内部,也可以不使用命令行选项,而通过指定far属性将变量存放在far数据段中。如果应用的near变量在8KB的near数据空间中存放不下,链接器将产生错误消息。(https://www.xing528.com)
2.near代码和far代码
具有near属性的函数(函数在彼此的32KW范围内)互相调用时比非near属性的函数效率高。如果已知应用程序中的所有函数都是near属性的,那么在编译每个模块时就可以使用默认的-msmall-code命令行选项来指示编译器采用更高效的函数调用形式。
如果这个默认的选项不适合,可以使用下面的可选方案:
1)可以使用-msmall-code命令行选项来编译应用程序的某些模块。在这种情况下,只有这些模块中的函数调用可以采用更高效的函数调用形式。
2)如果已使用-msmall-code命令行选项,那么编译器可能被指示对具有far属性的函数使用长函数调用形式。
3)命令行选项的作用域限于模块内部,可以不使用命令行选项,而通过在函数的定义和声明中指定near属性,指示编译器使用更高效的函数调用形式调用这些函数。
-msmall-code命令行选项与-msmall-data命令行选项的区别在于,采用前者时,为确保函数彼此“靠近”分配,编译器不需进行特别的操作;而采用后者时,编译器要将变量分配到特殊的段中。
如果函数声明为near,而其调用函数无法采用函数调用的更高效形式调用它时,链接器将产生错误信息。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。