



本小节介绍实时表情信息获取与重构平台,此平台使用计算机对视频流中的人脸实现实时的表情信息获取与表情重构。这里提到的表情信息获取,包括人脸及面部器官检测和表情识别(Facial Expression Recognition),其中人脸及面部器官检测是进行表情识别的基础。所谓表情重构(Facial Expression Reformation)是指利用计算机建立人脸模型,通过建立面部动作模型,模拟面部骨骼、肌肉运动,再现面部表情,从而表达虚拟人的喜怒哀乐。
实时重构平台的结构如下:
1)人脸及面部器官检测。人脸检测就是从包含人脸的环境中将人脸检测出来。面部器官检测是从已检测出的人脸中,将人的面部器官提取出来,这是表情信息获取过程中关键的一步,因为接下来的表情识别要以面部器官的运动趋势作为研究对象。本平台采用基于肤色模型和复合高斯模型的人脸及面部器官检测方法。
2)表情识别。在提取出面部器官之后,根据面部器官的相邻帧间信息,对面部器官的运动趋势进行分析,使用HMM实现实时的表情识别。
3)表情重构。这是本系统的重点工作。以Candide模型作为通用模型,对网格进行纹理贴图后,依据FACS,通过控制AU来改变人脸模型的面部表情,完成对人脸表情的重构。
下面将详细介绍系统所实现的各功能的模块。
1.表情识别模块
基于肤色的人脸检测方法对环境的稳定性要求比较高,但实现速度较快。通过实验比较众多的肤色模型,本平台采用了YCbCr颜色空间的肤色模型,在这一空间中,肤色呈现出良好的聚类性。因为肤色模型对光照比较敏感,受环境影响较明显,所以肤色模型稳定性较差,利用复合高斯模型对这一问题进行修正。复合高斯模型是由多个高斯函数的线性组合来模拟肤色分布,参数的增加使得复合高斯模型有更多的灵活性,更加适合用来描述复杂的分布情况。肤色的概率密度函数(PDF)可以定义为
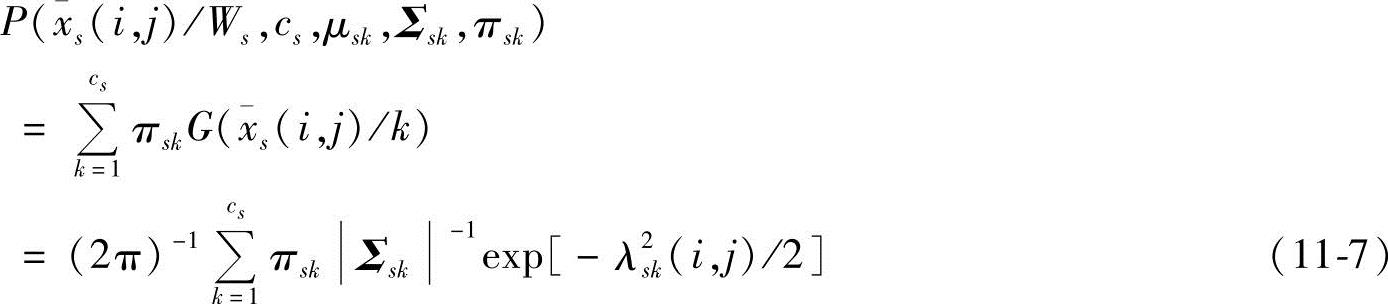
式中,cs表示模型中高斯分量的数量;πsk是一个复合系数,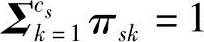 ;高斯分量为
;高斯分量为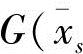
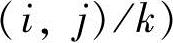 都有均值μsk和协方差矩阵Σsk。该复合概率密度函数的参数可以通过期望最大化(Expectation Maximization,EM)算法获得。
都有均值μsk和协方差矩阵Σsk。该复合概率密度函数的参数可以通过期望最大化(Expectation Maximization,EM)算法获得。
在实际操作时,先通过大量样本,训练出高斯复合模型的各个参数,然后针对每一个像素点,将其值代入高斯模型计算其属于肤色的概率,当计算得到的概率大于某一阈值时,认为其是肤色点,否则不是。
接下来进行面部器官检测。在定位面部器官之前,需要使用直方图均衡化、梯度照度修正和均方差标准化三步来实现光线的平衡化,使光线在人脸上的分布较为均匀。
眼睛的定位是其他器官定位的基础。通过人脸检测得到的人脸区域转化为灰度图,并用合适的阈值对其进行二值化后,可得到将面部器官与肤色分开的二值化图。然后,用下面的规则来搜索眼睛:
1)左右眼块的大小R1和R2相差不大;
2)左右单眼宽W1和W2与双眼中心距离D之比在一定范围之内;
3)左右眼的重心高度H1和H2相差不大;
4)左右眼宽高之比在一定范围内。
实验表明,通过上述四条规则的约束,总可以找到一对满足条件的连通区域,而这对连通区域恰好就是由两只眼睛所形成的区域。在找到了两只眼睛后,采用局部搜索的方法定位两个眼角点,即在眼睛所对应的局部区域中,搜索最左和最右的两个点作为左右眼角点,搜索最上和最下的两个点作为上眼皮上顶点和下眼皮下顶点。对于虹膜中心点的定位,采用了传统的积分投影的方法。在准确定位眼睛的基础上,又对嘴巴、眉毛和鼻孔进行了定位。
在检测出各个面部器官后,下面的任务就是分析面部表情。我们通过分析面部器官的运动信息来进行表情识别。
因为人类具有相同的面部骨骼及肌肉分布,即使是不同的人,对于同一种表情也会有相似的面部器官运动趋势,所以通过分析面部器官的运动信息,可以达到较好的表情识别效果。FACS作为一个通用的人脸动画编码规范,是表情重构工作的重要依据,同时通过分析FACS中AU与人脸表情的关系,可以发现,对一些完全不同的表情,某些面部器官的运动状态仍会存在一些相似之处。针对这一特点,表情识别应该采用一种能够有效描述状态与观察态之间关系的方法,HMM方法就是这样一种方法。
我们对每一种面部器官的动作建立一个HMM。先观察连续几帧间的同一器官的运动状态,根据HMM可以得出最佳的表情状态序列,然后统计出这一表情序列中各个表情状态的百分比,再根据各个器官的统计结果进行加权。一般而言,嘴部的运动最明显,对情感的表示也较为准确,所以赋予的权值较大,眼睛和眉毛的权值相对较小。通过加权得出综合的表情状态百分比,取比率最高的作为识别结果。下面介绍针对一种器官确定HMM参数的过程。HMM可以通过以下参数来描述:
1)N表示模型中的状态个数。令状态空间为S={S1,S2,…,SN},每一个状态对应一种表情状态。
2)M表示每一个状态可观察到的不同符号数。各个符号为V={V1,V2,…,VM},每一种符号对应该器官的一种运动状态。
3)状态转移概率分布A={aij}(其中,aij=P[qt+1=Sj|qt=Si],1≤i,j≤N)描述了各种表情之间的转移概率,状态转移概率分布由经验值预先设定。
4)状态j中可见符号的概率分布B={bj(k)}(其中,bj(k)=P[在t时刻出现符号为V|qt=Sj],1≤j≤N,1≤k≤M)描述了在一种表情状态中,一种器官各个运动状态的概率分布。
5)初始状态分布π={πj},其中πj=P[q1=Sj],1≤j≤N。初始状态分布也由经验值预先确定。
我们利用前向-后向算法解出最佳状态,定义:
①前向变量:
αt(i)=P(O1O2…Ot,qt=Si|λ) (11-8)
初始条件:α1(i)=πibi(O1),1≤i≤N
归纳:
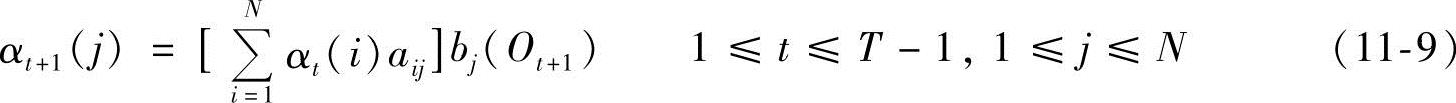
结果:

②后向变量:
βt(i)=P(Ot+1Ot+2…OT|qt=Si,λ) (11-11)
初始条件:βT(i)=1,1≤i≤N
归纳:
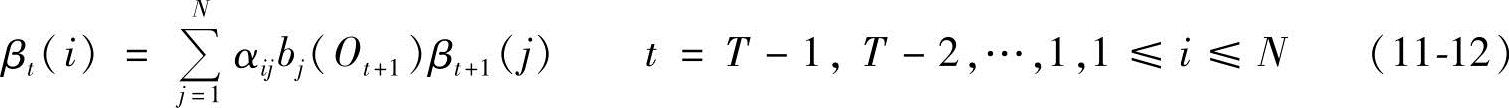 (https://www.xing528.com)
(https://www.xing528.com)
③变量:
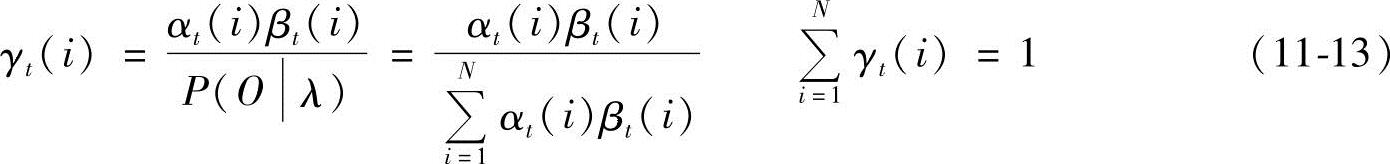
问题的解即表情状态qt:
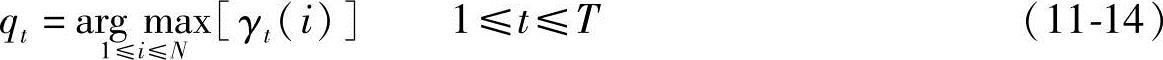
在得到状态序列qt后,就可按照上面提到的方法对各个状态序列中的统计结果进行加权综合,得出表情识别结果。
2.表情重构模块
选择Candide模型作为通用模型,它是一个基于图形数据的人脸模型。通过定义模型的顶点、表面、AUV,并选择尽量少的特征点,且涵盖尽量多的面部表情信息,借助OpenGL图形库,得到Candide模型。为了适应一个特定的人脸,需要对一般人脸模型进行变形,这一过程包括对特征点进行的变换和对非特征点进行的变换。对人脸模型变换后,对纹理贴图进行一些细致处理。对于二维人脸照片,从中恢复出视点参数,依据已构造的脸部模型,计算出脸部模型上每个顶点在纹理图像中的颜色信息,以增强人脸的真实感。
此模块仍然选用图11-2所示的包含76个节点的Candide模型作为通用模型,在程序中,定义m_iX[76]、m_iY[76]、m_iZ[76]来表示节点的坐标位置,并在初始化网格模型时,依据表11-1中各点的坐标,在函数InitFaceMesh()中对这些坐标点赋值:
m_iX[0] =0;
m_iY[0] =250;
m_iZ[0] =40;
m_iX[1] =40;
m_iY[1] =190;
m_iZ[1] =90;
m_iX[2] =0;
m_iY[2] =130;
m_iZ[2] =120;
m_iX[3] =0;
m_iY[3] =70;
m_iZ[3] =130;
……
绘制模型时选择绘制三角形,这样的三角形有100个,用TRIANGLE g_Triangle[]来表示构成三角形的顶点号:

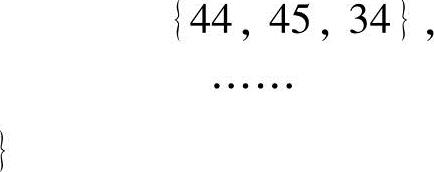
例如,{12,11,1}表示由12号、11号和1号三个顶点绘制的一个三角形。
在进行纹理贴图时,把二维图像依照各点的坐标与网格模型中的三角形顶点匹配,并把纹理图一块一块地贴到网格模型上。
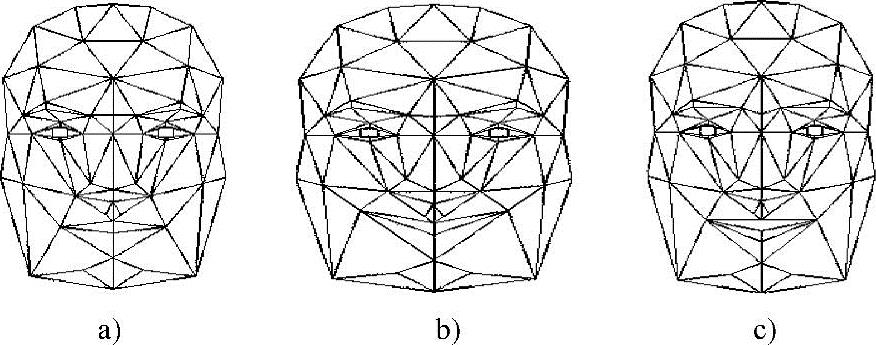
图11-6 平静、高兴、惊讶状态的网格模型
a)平静 b)高兴 c)惊讶
FACS是表情识别的重要依据,也是表情重构的基础。我们选择了FACS中对表情变化起主导作用的12组AU作为合成面部表情的12个基本单元。依照MPEG-4中对中性人脸的定义,可以认为中性人脸的表情表现为平静,把此时的AU值作为各个AU的初始状态。对比“平静”状态,“高兴”时,改变的AU有AU1、AU2、AU12,“惊讶”时,改变的AU有AU1、AU12、AU27。在确定好需要控制的AU后,要统计代表AU运动的运动向量所包含的节点在每一种表情中,相对于初始状态(平静)的位置变化。程序实现时,12组AU在初始状态时,初始值均设为0,12组AU与Candide模型的76个节点的坐标值相关联,当表情识别模块识别出表情变化时,表情重构模块将按照所识别的表情,改变相应的AU值,随着AU值的改变,Candide模型的节点坐标也发生改变,OpenGL中使用一系列函数对图形进行重新绘制。由于绘制模型时使用的是三角形的顶点数组TRIANGLE g_Triangle[],虽然随着AU值的改变,Candide模型的节点坐标发生改变,但顶点号并没有变化,所以只是改变了一些三角形的形状,并没有改变各个三角形的总体构成,也没有改变人脸网格模型的结构,而且纹理贴图与网格模型之间的关系也没有发生变化。

图11-7 实时表情信息获取与重构平台实验结果
a)平静 b)高兴 c)惊讶
我们对最具有代表性的三种表情——平静、高兴、惊讶进行重构。三个表情状态的网格模型如图11-6所示。
3.实验结果
图11-7是实验结果片断,依次为平静、高兴、惊讶。
实验以每秒15帧的速率,在Pentium IV 2.0GHz CPU且没有任何特殊硬件的PC上,对于10个不同人的不同表情统计识别结果表明,识别的正确率达到70%左右,对所识别表情,可以准确地进行实时表情重现。这表明所提出的方法是有效可行的。未来工作要在表情识别的准确性上继续进行研究。
实时表情信息获取与重构平台的应用前景十分广泛。例如,网络视频中,应用此平台可以只传送人脸表情参数,而不需实时传送大量的视频信息,这样就节约了网络带宽,同时能够得到较准确的人脸面部信息。娱教(Edutainment)技术中,教师可以通过此平台来判断学生当前的情绪变化,与学生进行情感交互。在智能交通系统中,可以依此判别驾驶员是否处于疲劳驾驶状态,并及时警示这类现象,避免由此引发的交通事故。情感机器人是人工智能和人工心理理论不断发展的产物,将实时表情信息获取与重构平台模块移植到单片机或机器人身上,是让机器拥有识别、理解和表现人类情感的能力的重要一步。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。