



最大互信息法和最小鉴别信息法都以减少HMM分类误差作为间接目标,但是这两种方法都很难从理论上证明训练后的HMM能够有效降低错误率。参考文献[25-27]提出了一种基于最大模型距离(MMD)的HMM训练方法。该方法能够使得训练过程自动聚焦于那些易混淆样本,可以有效地提高HMM对己类和非己类样本的识别率。
本小节对参考文献[25-27]所用模型距离进行了修正,重新定义了最大模型距离准则。考虑到竞争样本在某些模型下输出概率非常小,其对模型参数估计的影响也非常小,完全可以被忽略不计,基于这种考虑,本小节引入最佳竞争模型集代替原有模型距离定义中的所有竞争模型,并通过引入参数来控制竞争模型集对当前HMM模型参数估计的综合影响程度,重新修正了模型距离定义,称之为改进的最大模型距离(Improved Maximum Model Distance,IMMD),并基于该IMMD推导了新的HMM训练算法,并将该HMM训练算法应用于面部表情识别。采用光流算法提取面部表情特征序列,最后基于改进HMM算法和BP神经网络构建了一个混合分类器,实验结果表明了该方法的有效性。
1.IMMD准则函数
设HMM表示为λ=(π,A,B),其中π为初始状态概率,π={πi};A为状态转移概率,A={aij};B为观察向量的混合高斯概率密度函数,B={bj(o)}。设Λ为HMM模型集,Λ={λ1,λ2,…,λV};V为HMM模型个数;Nv和Mv分别为模型λv的状态数和每个状态所包含的高斯混合元个数,则训练样本集为

式中,Ovk为模型λv的第k个训练样本,Kv为模型λv的训练样本数,且有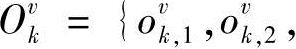
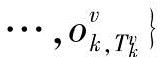 ,Tvk为样本Ovk的观察向量序列长度。最大模型距离(MMD)准则可以表示为
,Tvk为样本Ovk的观察向量序列长度。最大模型距离(MMD)准则可以表示为
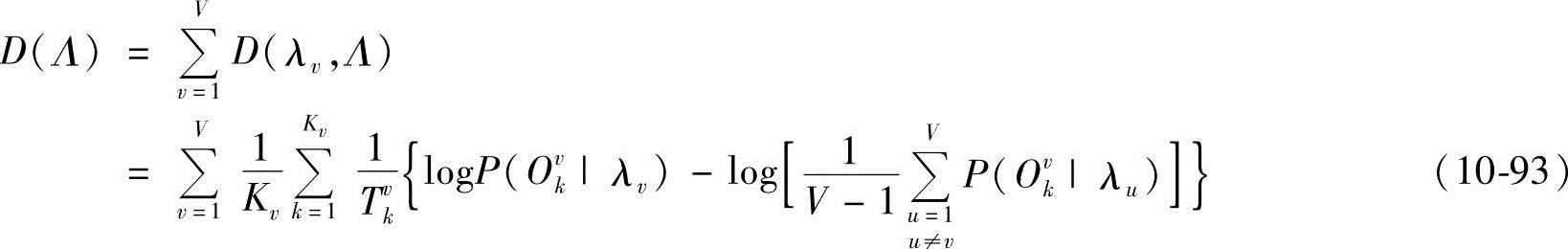
本小节将D(λv,Λ)修改为
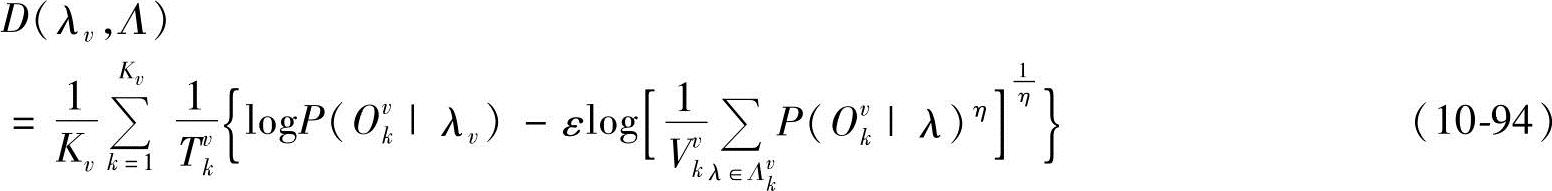
式中,0<ε<1;Λvk为样本Ovk的最佳竞争模型集,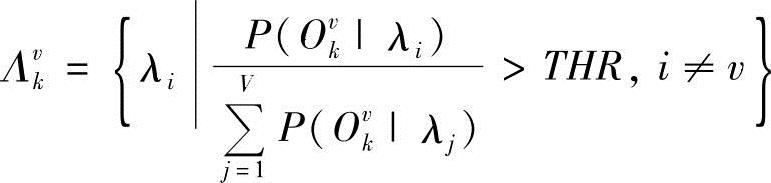 ;0<THR<1;Vvk为Λvk中模型个数。从而得到IMMD准则函数为
;0<THR<1;Vvk为Λvk中模型个数。从而得到IMMD准则函数为
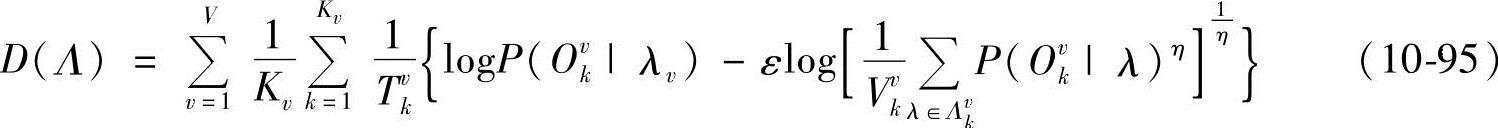
对比式(10-93)和式(10-95)可知:
1)若ε=1,且THR=0,则式(10-93)与式(10-95)等同。
2)式(10-95)用最佳竞争模型集代替了式(10-93)中的所有竞争模型,对于HMM分类器来说,如果正确模型的输出概率能大于最佳竞争模型子集的输出概率,则该HMM就能作出正确分类,此时完全可以不考虑其他竞争模型的影响。因此,从这个角度考虑,采用最佳竞争模型集代替所有竞争模型更为合理。
3)最佳竞争模型集的引入可以进一步减少计算量,最佳竞争模型集大小由THR值控制。
4)改变η大小,可以调整不同竞争模型的影响程度。
5)参数ε的引入可以控制最佳竞争模型集的整体影响程度,特别是,ε=0时,该方法退化为经典的Baum-Welch方法。
2.基于IMMD的HMM参数估计算法
考虑有约束优化问题,得
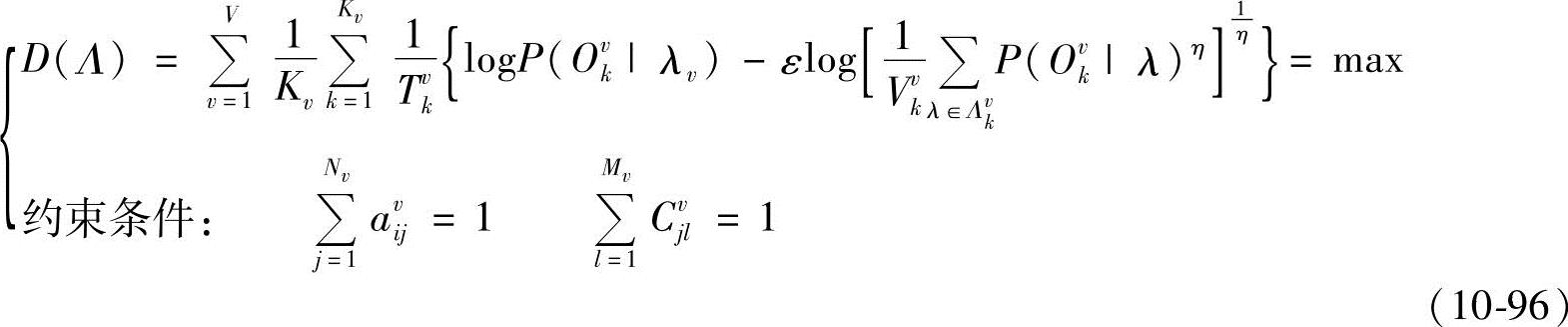
构造拉格朗日函数为
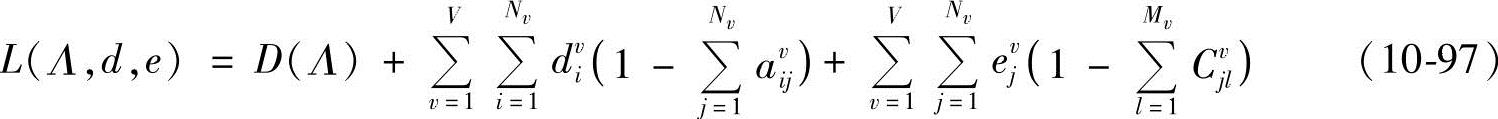
式中,dvi、evi为拉格朗日乘子;avij为模型λv状态i转移到状态j的概率;Cvjl为模型λv时状态j中第l个高斯混合元的混合系数;μvjl和Σvjl分别为与模型λv时状态j中第l个高斯混合密度函数N(o,μvjl,Σvjl)对应的均值向量和协方差矩阵(取对角型)。
令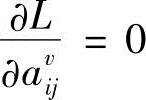 、
、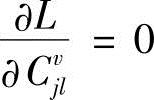 、
、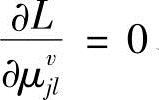 、
、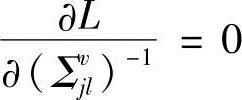 ,得到
,得到
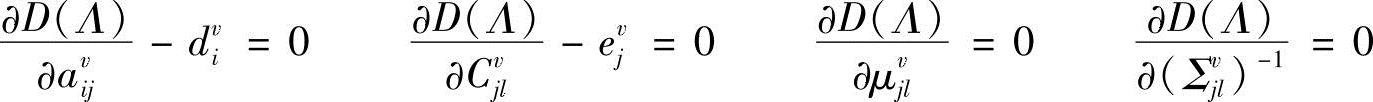
并且
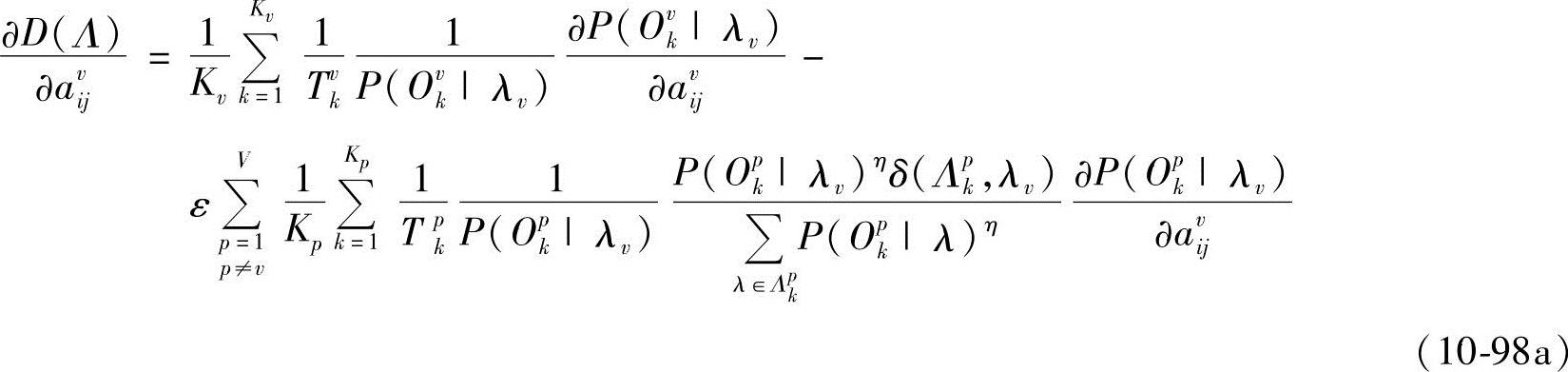
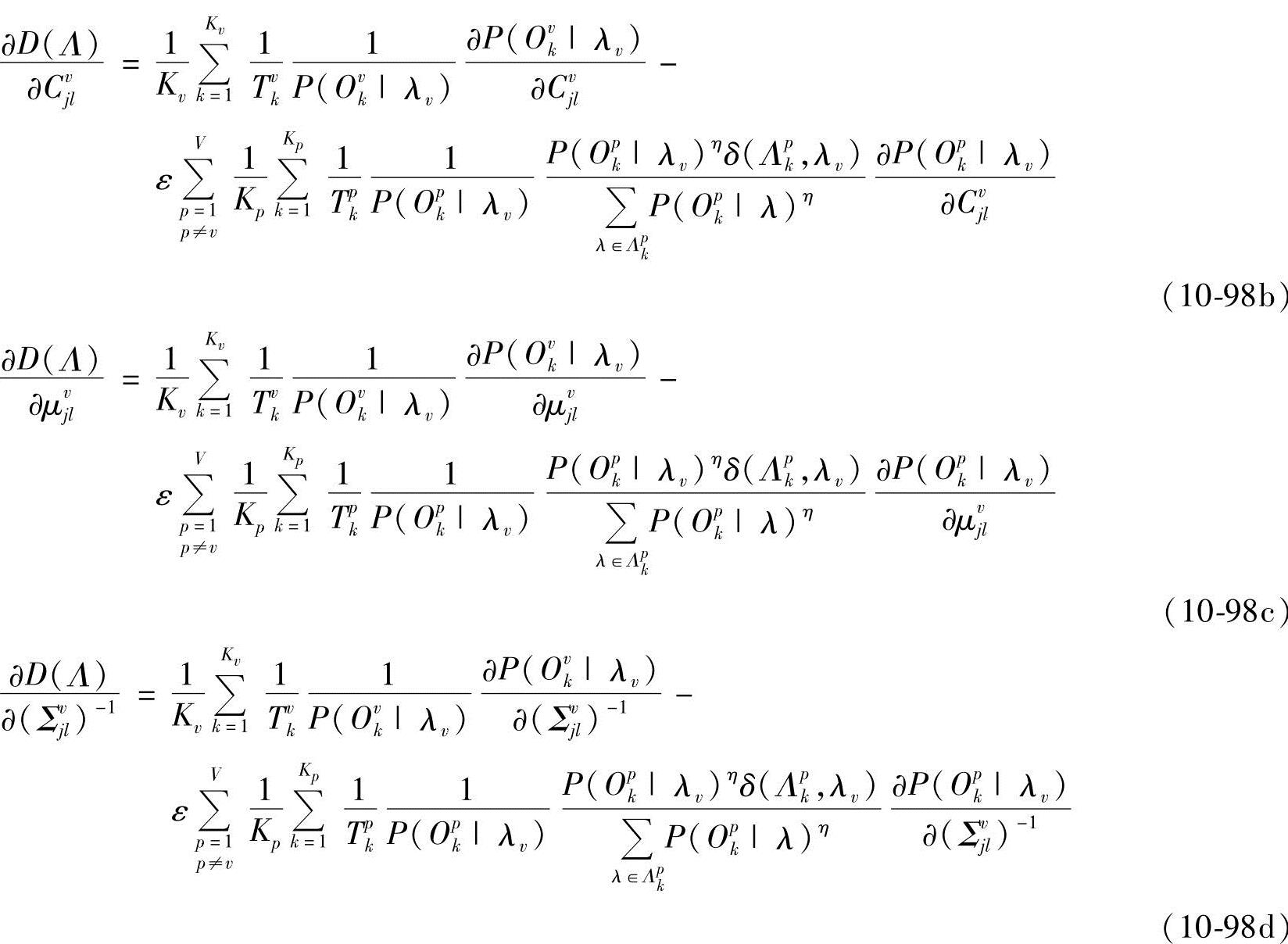
式中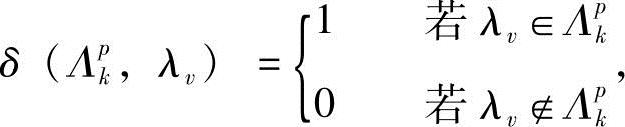 而
而
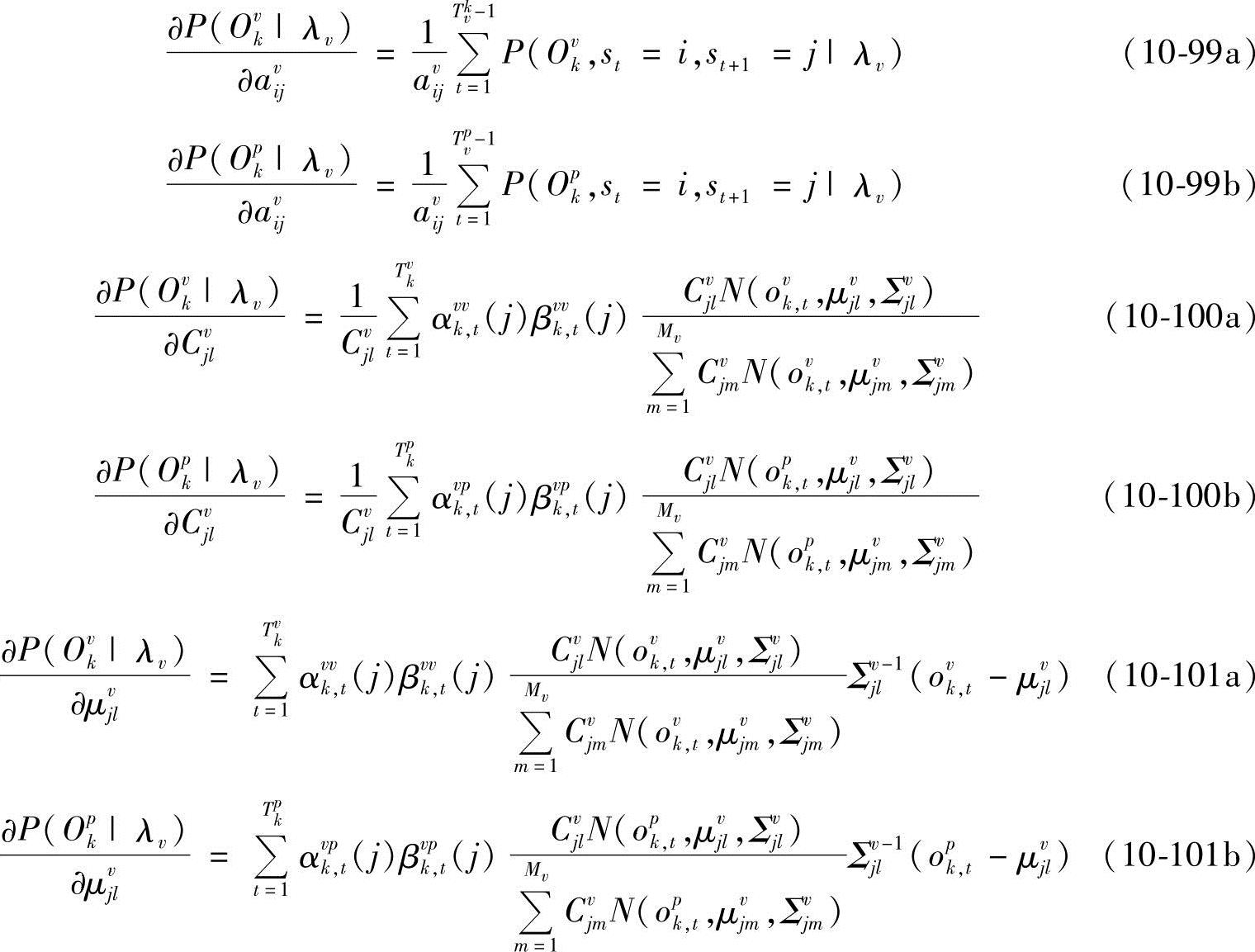
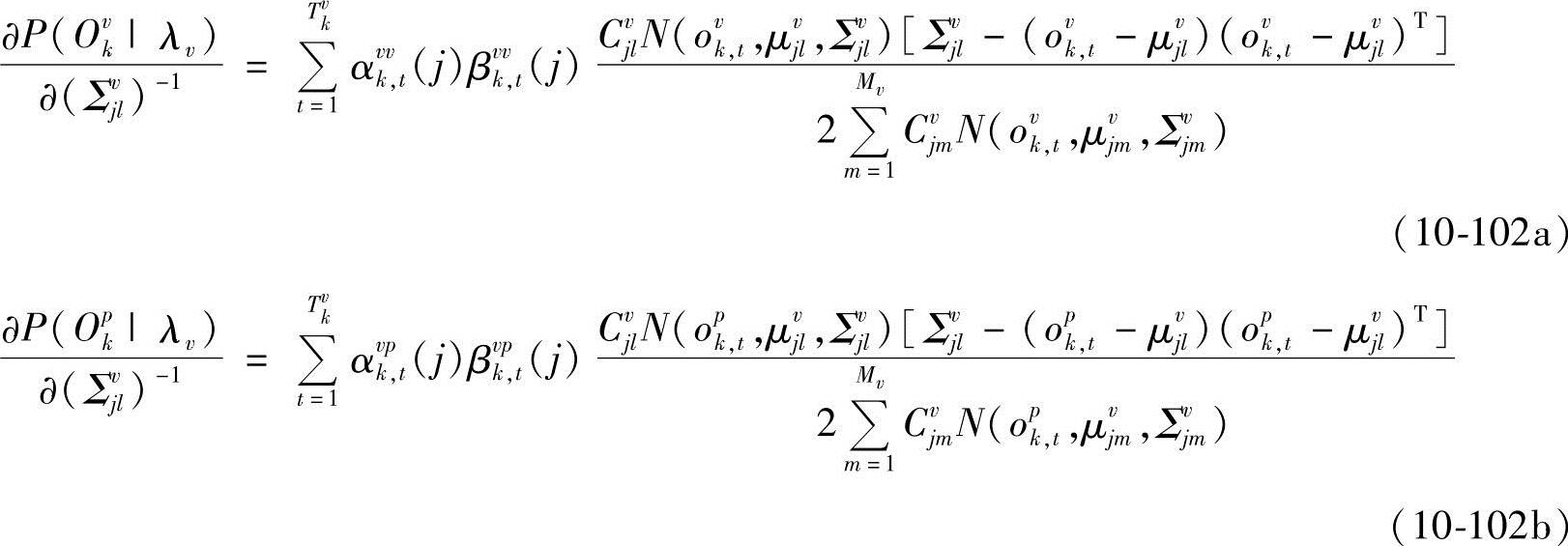
式中,αvvk,t(j)和βvvk,t(j)分别为给定第v类中第k个样本在模型为λv时,t时刻处于状态i的前向概率和后向概率;αvpk,t(j)和βvpk,t(j)分别为给定第p类中第k个样本在模型为λv时,t时刻处于状态i的前向概率和后向概率。由∂D(Λ)/∂avij-dvi=0,得
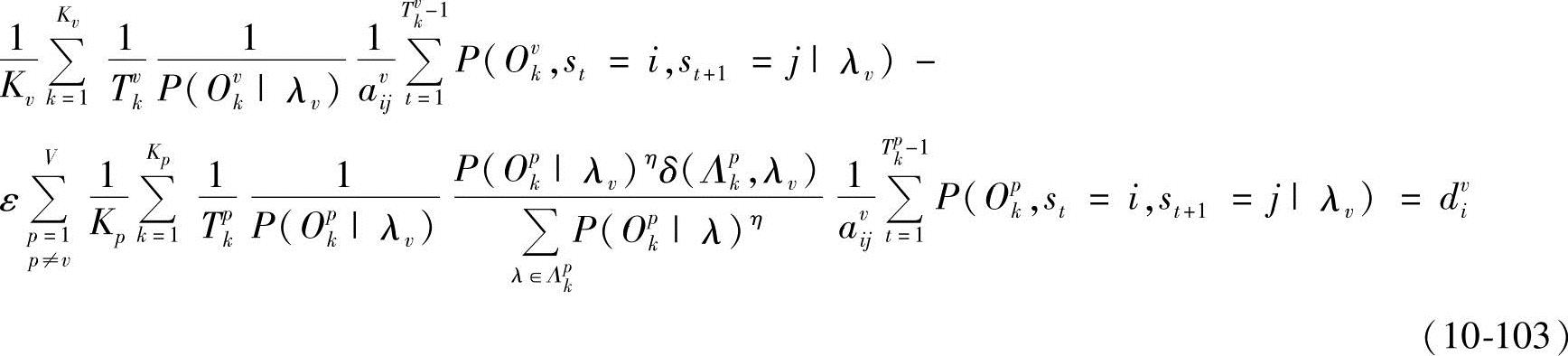
从而
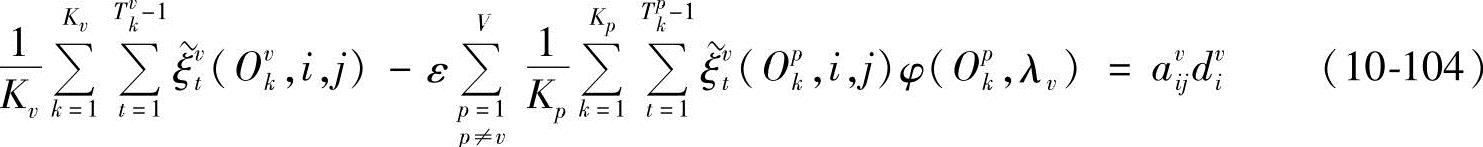
式中,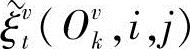 、
、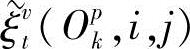 为过渡概率,
为过渡概率,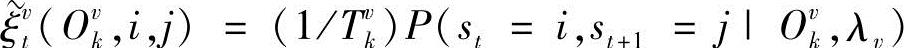 ,
,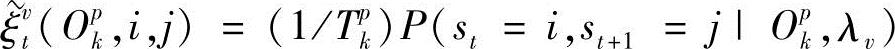 ;φ(Opk,λv)为相对输出概率,
;φ(Opk,λv)为相对输出概率,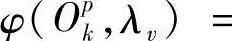
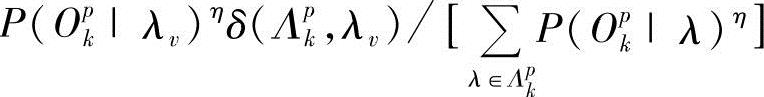 。
。
将式(10-104)两边对j求和,并注意到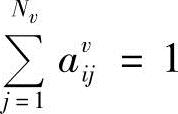 ,可得
,可得
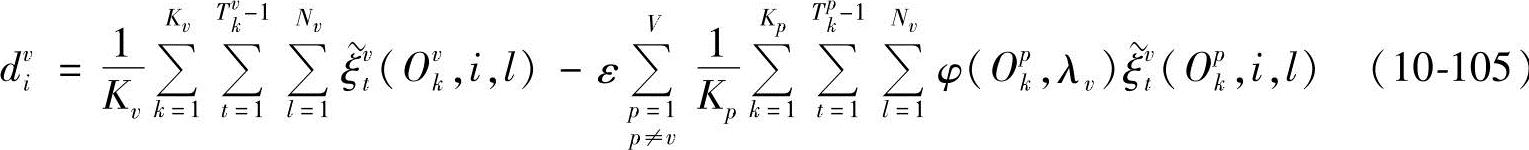
把式(10-105)代入式(10-104),得
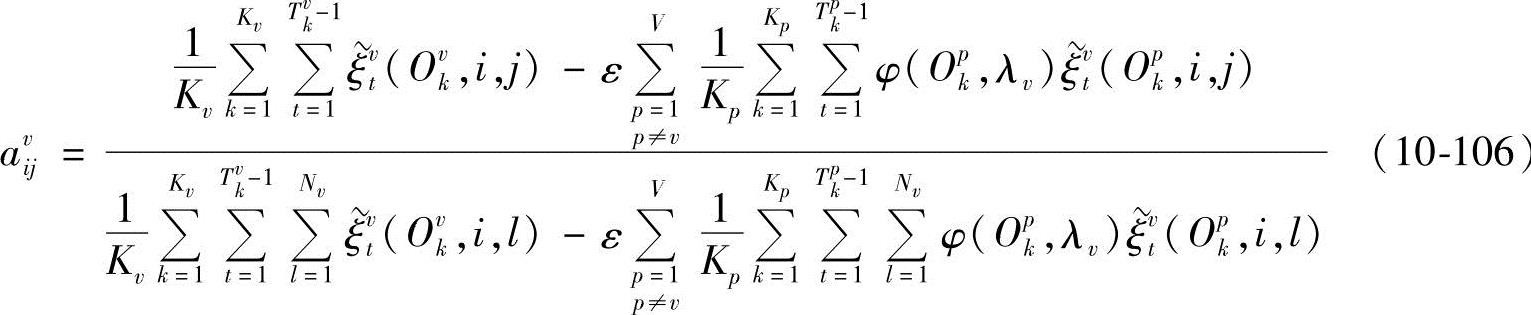
由∂D(Λ)/∂Cvjl-ejv=0,得
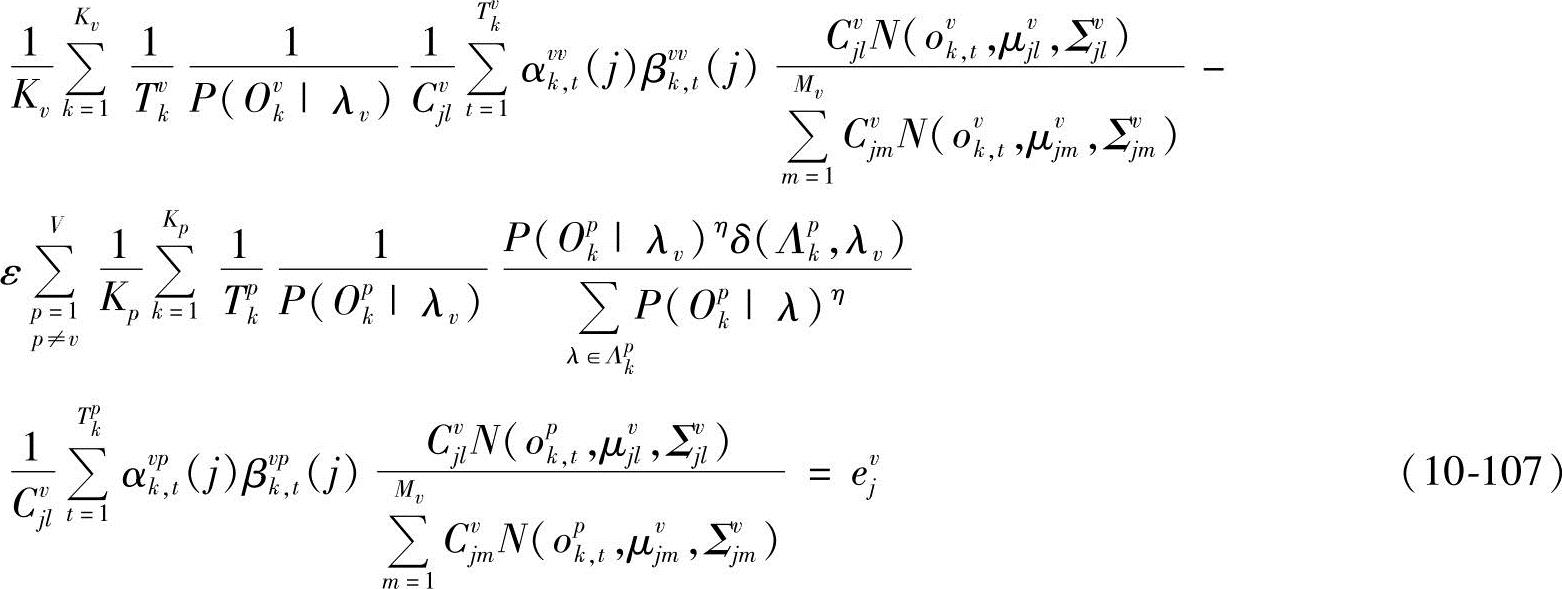
从而
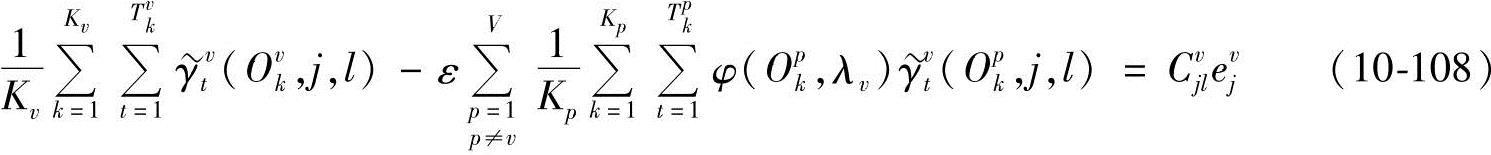
其中,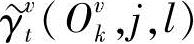 、
、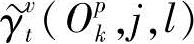 为混合输出概率,
为混合输出概率,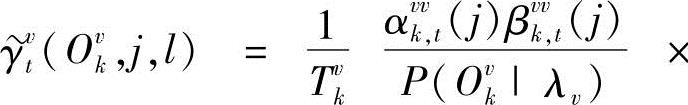
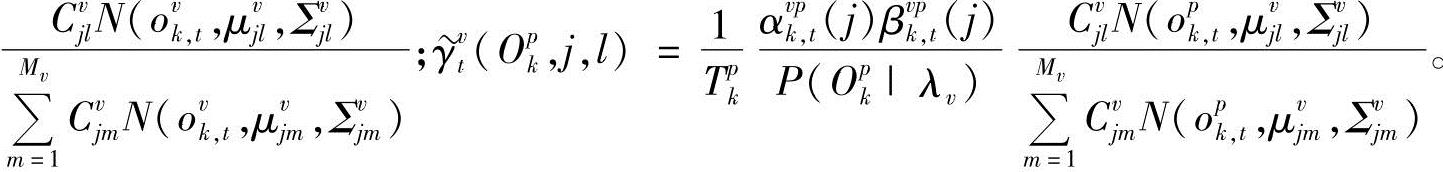
将式(10-108)两边同时对l求和,并注意到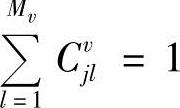 ,得
,得
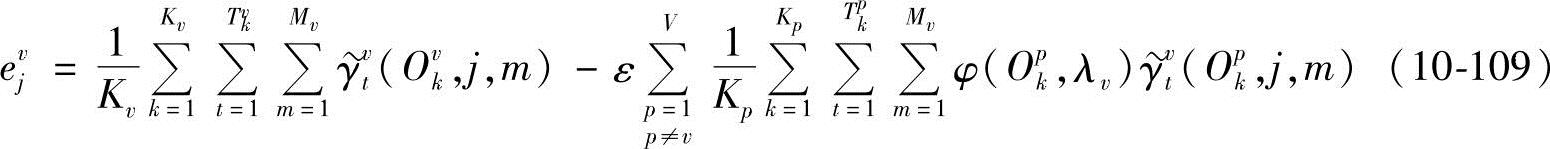
把式(10-101)代入式(10-100),得
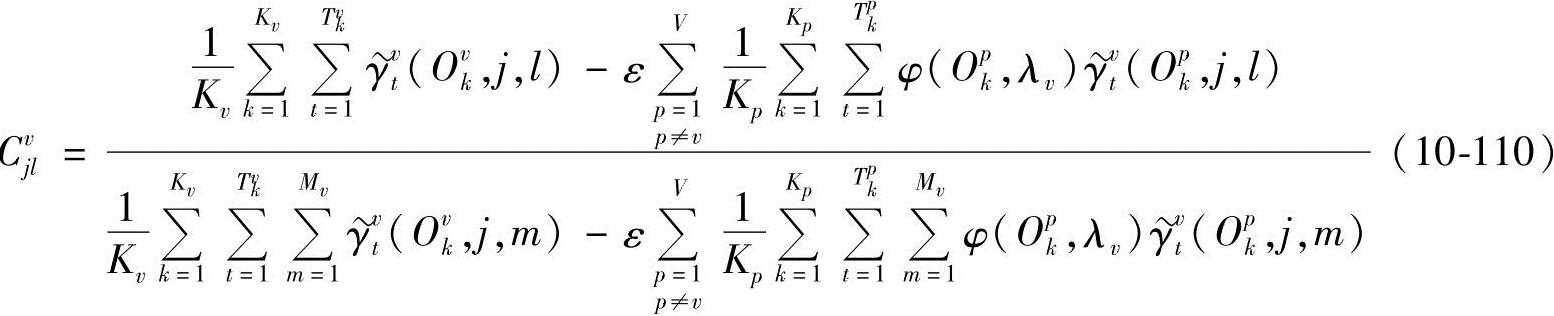
由∂D(Λ)/∂μvjl=0,得
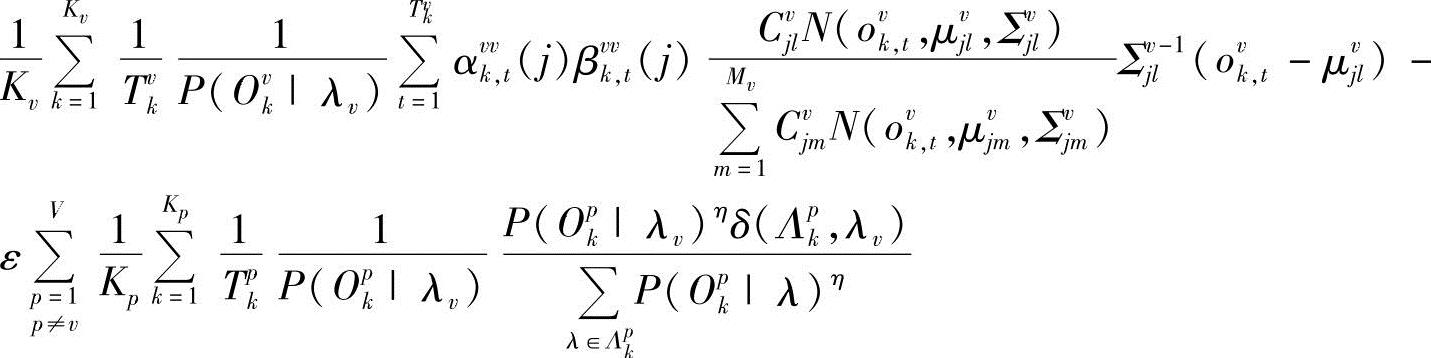
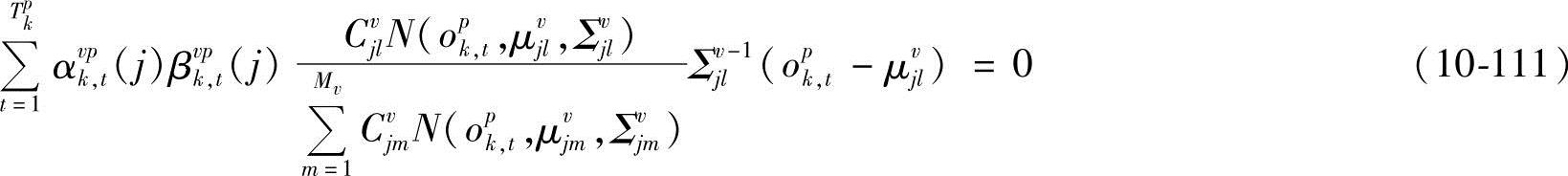
从而
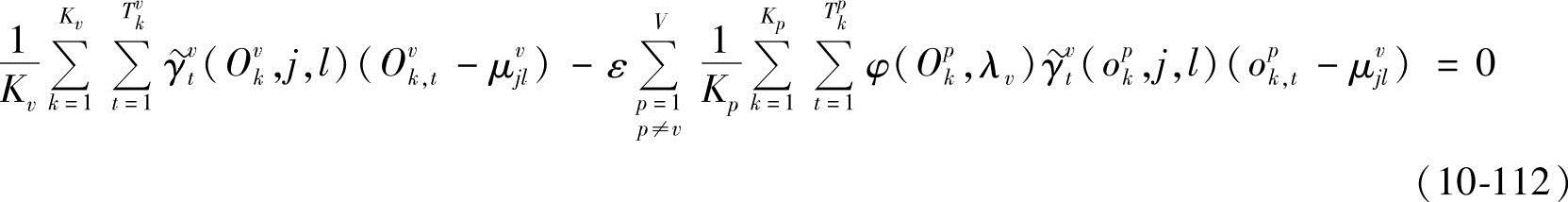
所以
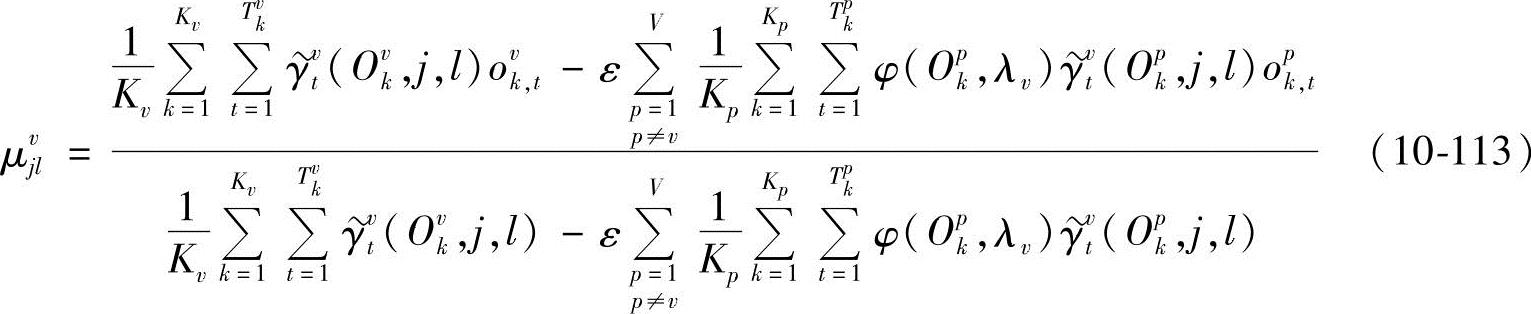
由∂D(Λ)/∂(Σvjl)-1=0,得(https://www.xing528.com)
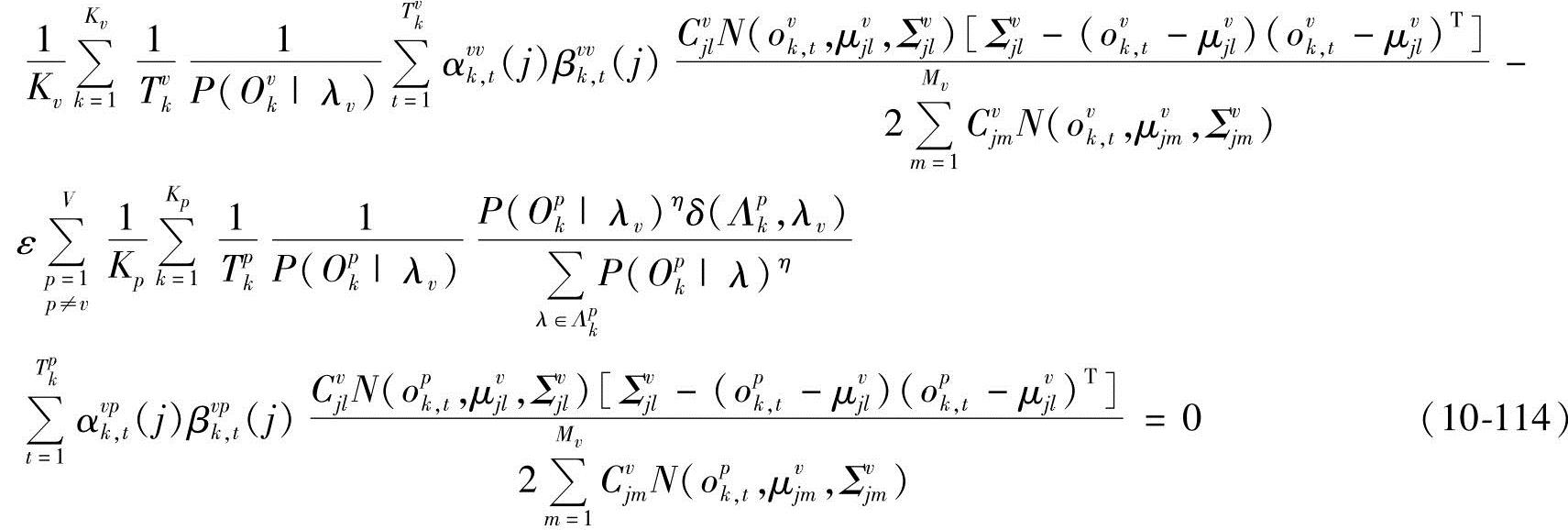
从而
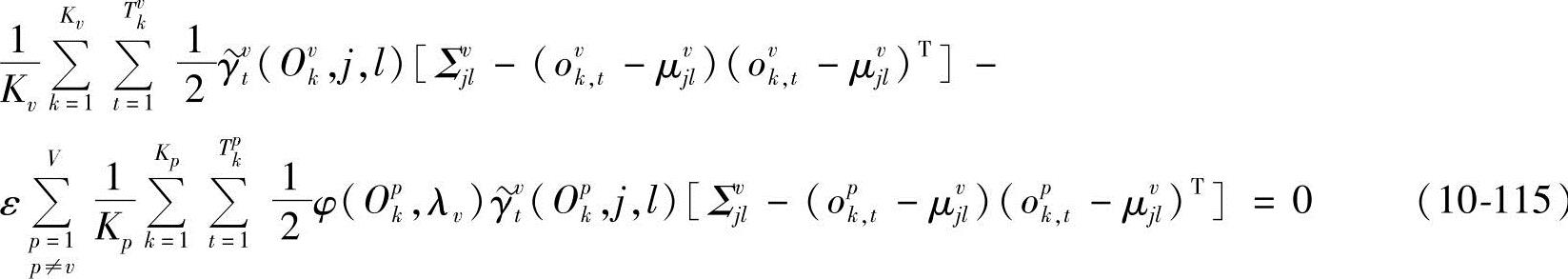
所以
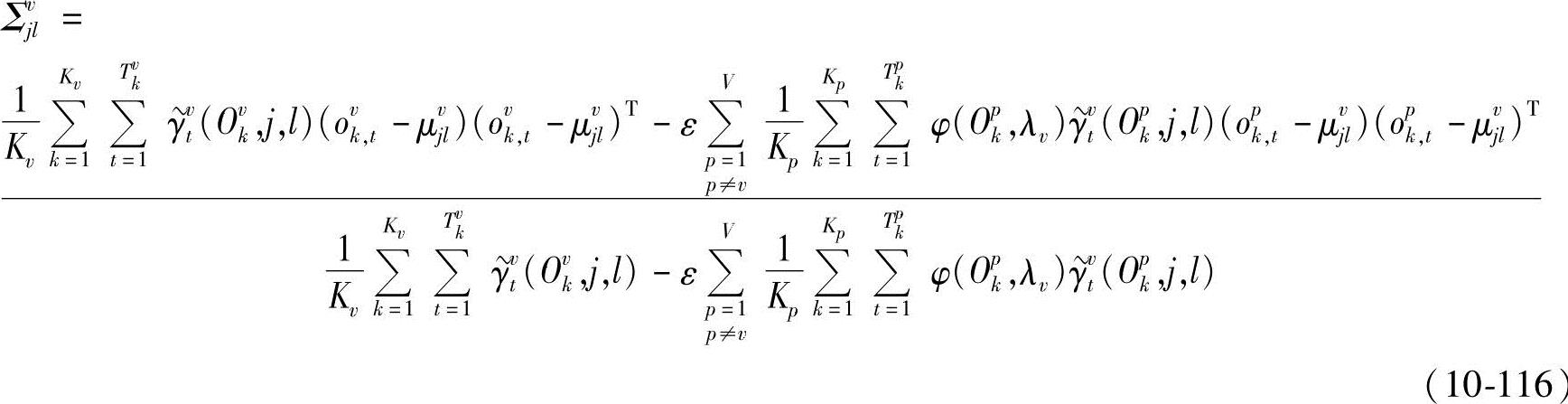
重新考虑式(10-94),当η→∞时,有
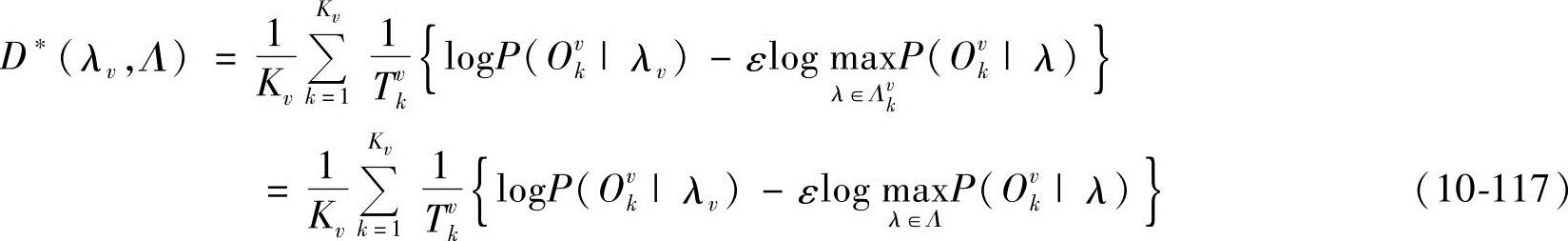
从而有
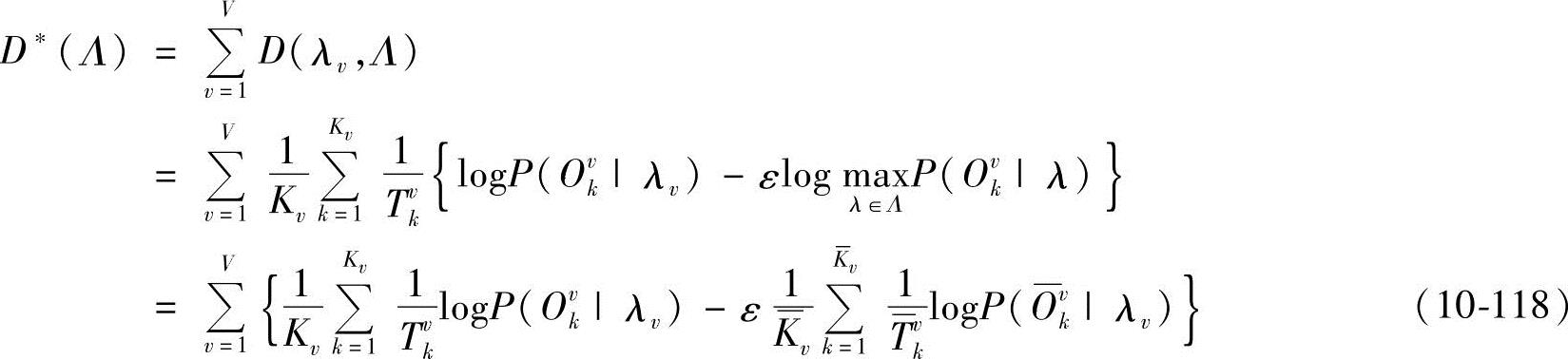
设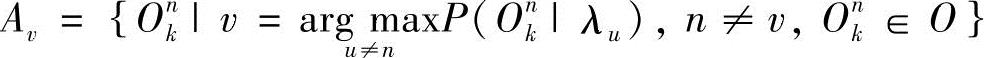 ,不妨记
,不妨记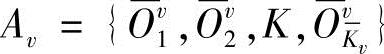 ,则有Ovk∈Av。
,则有Ovk∈Av。
对比式(10-95)和式(10-118)可以发现,对于式(10-96),所有HMM参数估计必须同时进行,对于式(10-110),各个HMM参数可以单独估计,其算法流程等同于Baum-Welch算法。要使D*(Λ)=max,可重复上述推导过程,可得到
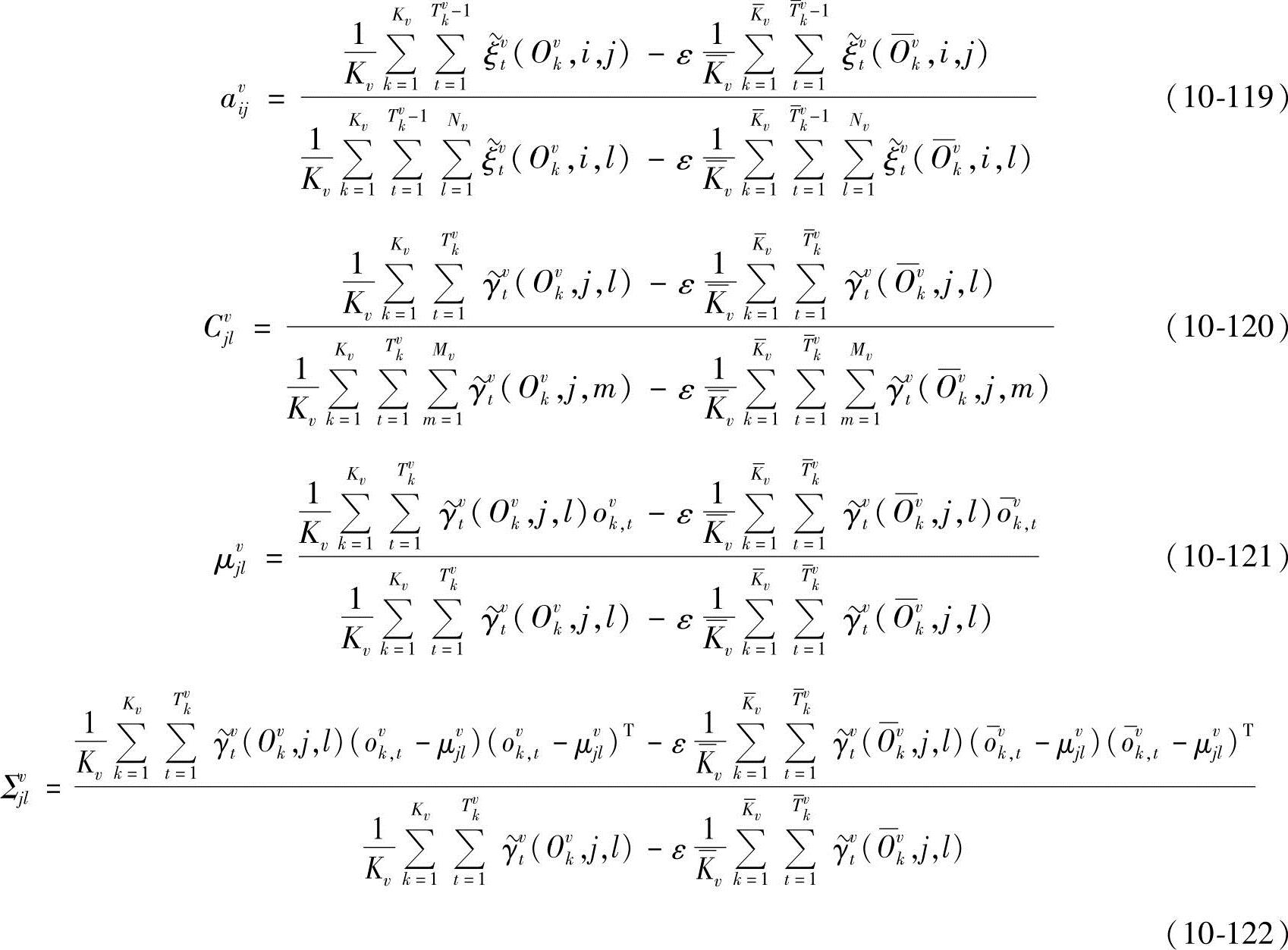
在参数重估过程中,为保证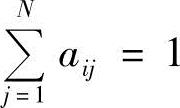 、
、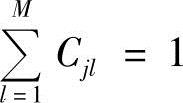 ,必须对每次估计的参数进行归一化处理:
,必须对每次估计的参数进行归一化处理: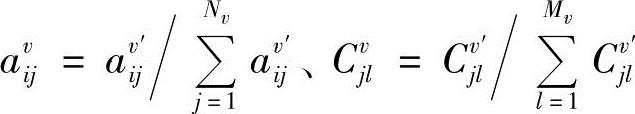 ,其中av′ijCv′jl为重估值。
,其中av′ijCv′jl为重估值。
至此,IMMDE算法基本完成,整个算法概括如下:
1)HMM参数初始化。采用经典Baum-Welch算法估计HMM参数,把估计结果作为本小节IMMDE算法中HMM参数的初始值。
2)在训练初期,由于训练样本在各个模型下输出概率相差不是很明显,而在训练后期样本输出概率相差明显,因此对参数η进行自适应变化,即η(loop)=cloop,其中c为一常数,c>1;loop为迭代步骤。
3)对每个训练样本,分别计算前向概率、后向概率、过渡概率、相对输出概率和混合输出概率,并计算每个训练样本的最佳竞争模型集Λvk,重新分配各个模型训练样本集Av。
4)利用式(10-106)、式(10-110)、式(10-113)、式(10-116)和式(10-119)~式(10-123),重估HMM参数,并归一化处理。
5)判断参数估计是否达到预定迭代步数或预定精度,若是,则结束,否则转步骤2)。
3.IMMD参数估计算法在面部表情识别中的应用
基于IMMD算法的面部表情识别系统流程如图10-25所示。
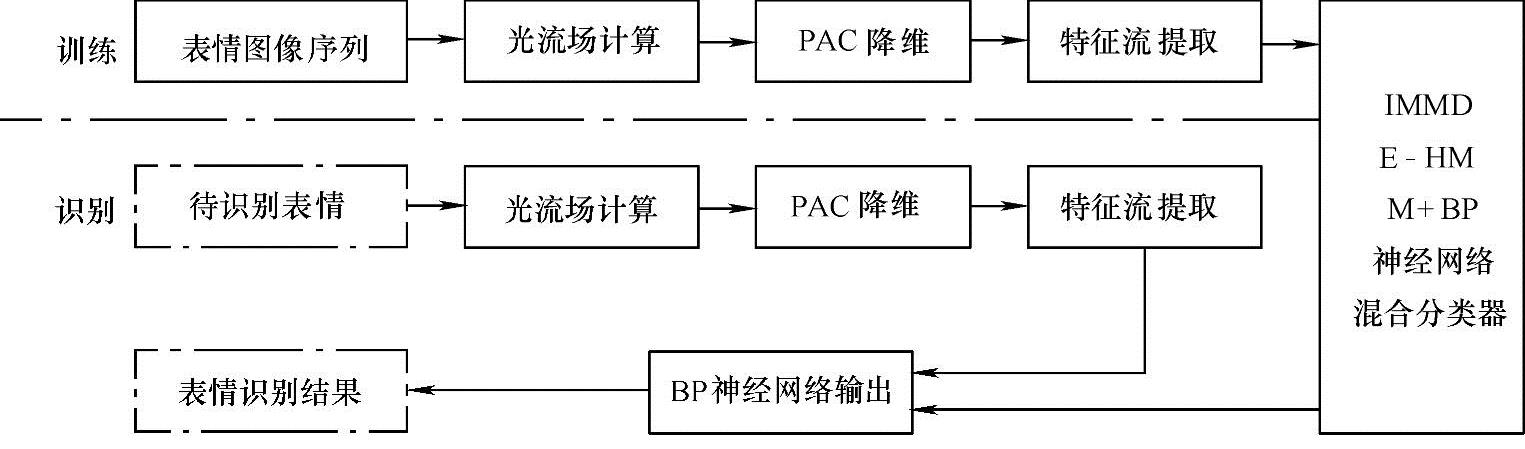
图10-25 基于IMMD的HMM算法面部表情识别系统训练和识别流程
同10.4.3节一样,先采用改进光流法对面部表情图像序列计算光流场,得到表征面部表情变化的光流场。在得到光流场后,分别对水平方向u和垂直方向v的运动图像进行归一化和标准化,采用PCA法分别求取u方向和v方向的基底,表情图像的特征向量是有u和v分量的投影系数串联得到。对于含有某种表情变化的图像序列,先依次求出各帧图像中的速度场在各自u、v基底上的投影,并把u、v串联起来构成面部表情特征向量,整个序列就是面部表情特征流,用来作为HMM输入信号。
为了充分利用HMM和BP神经网络的优点,本小节仿照10.4.3节构建了基于IMMIE的HMM和BP神经网络混合分类器,把BP神经网络作为二次分类器(见图10-26),其算法过程如下:
1)利用改进光流算法计算面部表情图像序列的光流场,并对光流场利用主成分分析(PCA)进行数据压缩,得到面部表情的特征向量序列。
2)对上述得到的特征向量序列,利用IMMDE算法训练HMM。
3)把各个HMM输出概率组合成一个新的向量,并把它作为BP神经网络的输入信号,训练BP神经网络分类器。
4.实验结果及分析
从CMU人脸数据库中,随机抽取了14个人的面部表情图像序列,并把10人的面部表情图像序列作为训练样本,其余4个人的面部表情图像作为测试样本。对每种表情图像分别构建了不同的HMM,HMM均选择左右结构,其状态数为4,各个状态取高斯混合元个数为M=3,分别利用式(10-106)、式(10-110)、式(10-113)、式(10-116)和式(10-118)~式(10-122)训练HMM。把HMM输出作为BP神经网络分类器的输入信号,再训练BP神经网络分类器。其中,BP神经网络输入输出节点均为6个,其隐节点数通过实验调整。为便于比较,同时采用Baum-Welch法训练HMM,其测试结果如图10-27、图10-28所示。其中,IMMDE1指基于式(10-106)、式(10-110)、式(10-113)、式(10-116)的HMM训练算法,IMMDE2指基于式(10-118)~式(10-122)的HMM训练算法,MMDE指基于式(10-93)的HMM训练算法。
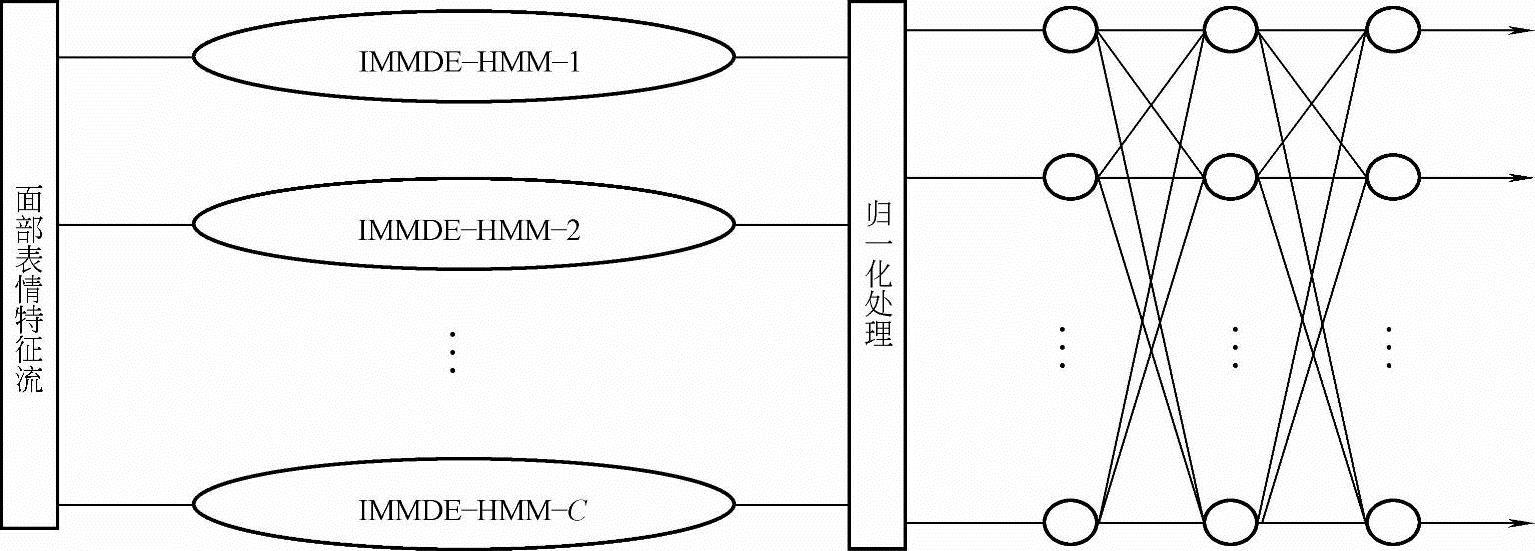
图10-26 IMMDE-HMM/BP神经网络混合分类器
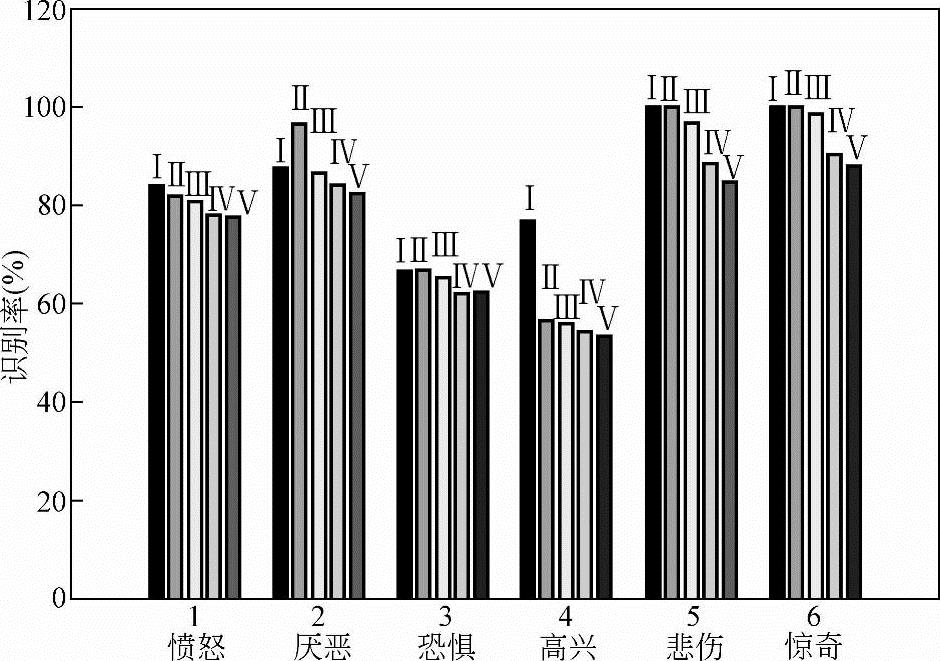
图10-27 基于Hessian矩阵光流法的表情特征提取下,IMMD法与其他方法的比较
图10-27所示为采用基于Hessian矩阵的光流算法提取面部表情光流场,经PCA变换得到面部表情特征流,构建了IMMDE-HMM/BP神经网络分类器。Ⅰ、Ⅱ、Ⅲ、Ⅳ分别为采用IMMDE1/BP神经网络、IMMDE2/BP神经网络、MMDE/BP神经网络和Baum-Welch/BP神经网络四种方法的识别结果。方法Ⅴ为采用Lucas-Kanade光流法提取表情特征流,采用Baum-Welch/BP神经网络分类器得到的识别结果。
图10-28所示为采用非刚体光流算法提取面部表情光流场和采用PCA变换得到面部表情特征流,构建了IMMIE-HMM/BP神经网络分类器。Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ分别为采用IMMDE1/BP神经网络+一阶div-curl约束光流法、IMMDE1/BP神经网络+二阶div-curl约束光流法、IMMDE2/BP神经网络+一阶div-curl约束光流法、IMMDE2/BP神经网络+二阶div-curl约束光流法和Baum-Welch/BP神经网络+Lucas-Kanade光流法的五种方法的识别结果。
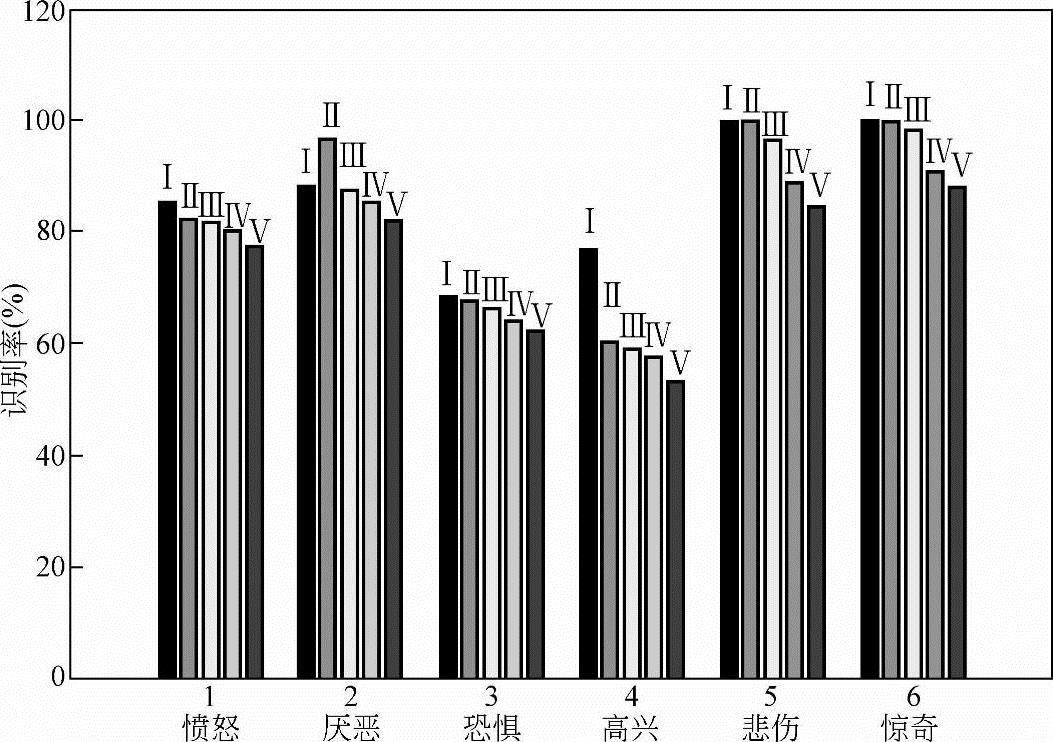
图10-28 基于非刚体光流法的表情特征提取下,IMMD法与其他方法的比较
由图10-27、图10-28可以看出,四种方法对悲伤、惊奇、厌恶三类识别率较高,这主要是因为这三类有着较之其他类别更明显的几何特征,如惊奇表情的眼睛张得比较大,上眼皮被抬高,下眼皮下落,其嘴巴也大幅张开,以至于唇和齿分开。相比之下,高兴和恐惧这两类识别率普遍较低,只有60%左右,主要是因为高兴和恐惧在表现时脸部器官有较多相似运动特征,如两者的嘴巴部分都处于张开状态,且张开程度相似,在试验中发现影响高兴识别率的主要是恐惧,而影响恐惧类表情识别率的除了高兴外,还有厌恶和愤怒两类表情。此外,由图也可看出,本节提出的两种改进HMM方法(Ⅰ和Ⅱ)比其他方法(Ⅲ、Ⅳ和Ⅴ)对各类表情的识别效果均有不同程度的提高。由于测试时采用的是陌生人脸的六类表情,这些人脸在训练样本中未出现,由这点可以进一步体现本节所述方法的鲁棒性。
如图10-29、图10-30所示,所有结果均是在采用10个人的表情图像序列作为训练样本时得到的。为了进一步探讨参与训练人数和测试结果的关系,分别采用6~10个人的样本参与训练分类器,其余人的表情图像序列作为测试样本,其结果如图10-29、图10-30所示。
如图10-29所示,“+”“o”“x”“□”表示的曲线分别为采用IMMDE1/BP神经网络、IMMDE2/BP神经网络、MMDE/BP神经网络和Baum-Welch/BP神经网络方法在采用Hessian矩阵光流法提取表情特征流后得到的分类结果,“▽”为采用Lucas-Kanade光流法提取表情特征流,并采用Baum-Welch/BP神经网络分类器得到的识别结果。如图10-30所示,“+”“o”“x”“□”“▽”分别为IMMDE1/BP神经网络+一阶div-curl约束光流法、IMMDE1/BP神经网络+二阶div-curl约束光流法、IMMDE2/BP神经网络+一阶div-curl约束光流法、IMMDE2/BP神经网络+二阶div-curl约束光流法和Baum-Welch/BP神经网络+Lucas-Kanade光流法等五种方法在不同训练样本集下的识别结果。
如图10-29、图10-30所示,随着参与训练的人数增加,各种方法识别率呈上升趋势,在参与训练人数较少时(6人),本节所述的改进的HMM方法能达到70%以上的识别率,而其他方法则识别率只有60%~70%,随着参与训练人数的增多,本节所述的方法一直保持较高识别率,可以预见,随着参与训练人数的继续增多,本节所述的改进的HMM方法识别率还会进一步提高。
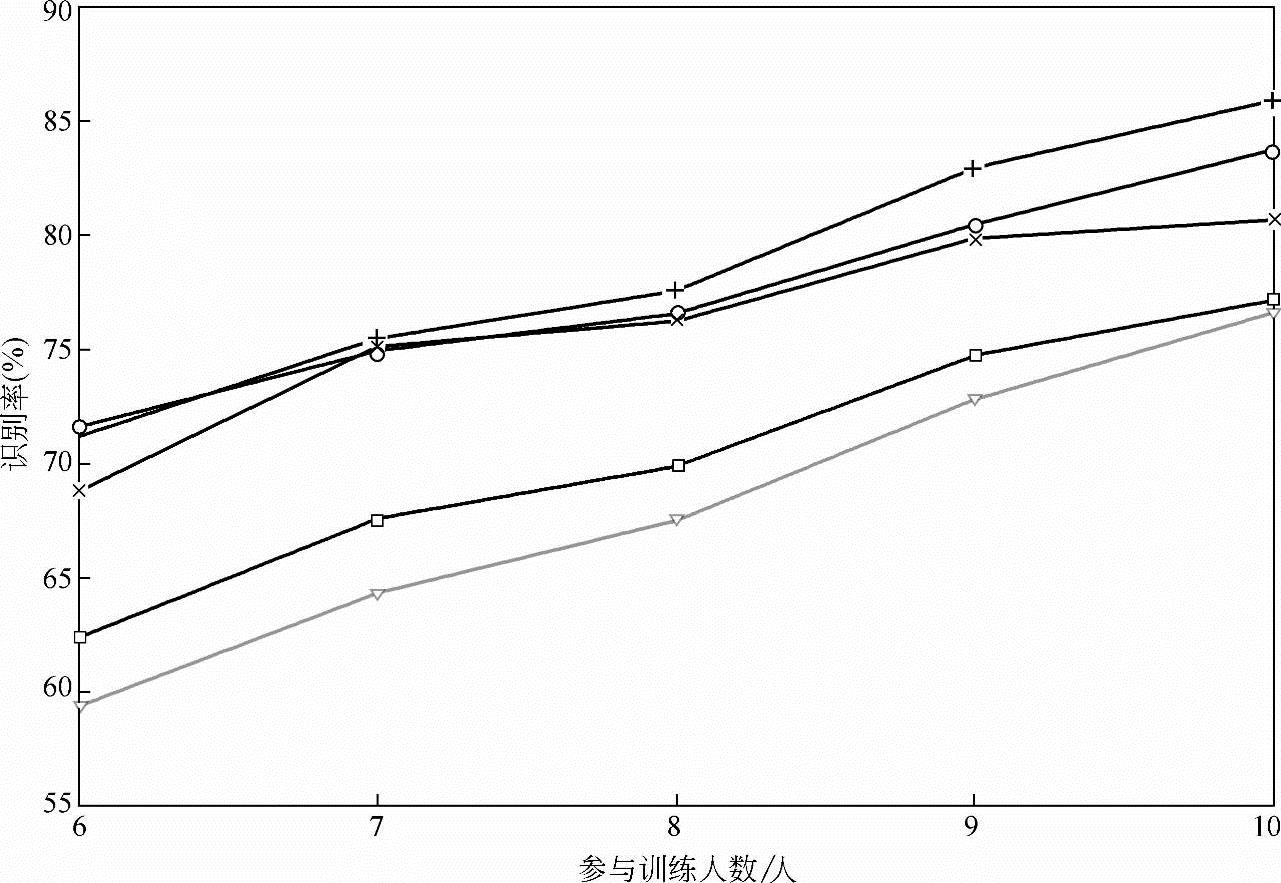
图10-29 基于Hessian矩阵光流法的表情特征提取下,参与训练人数与识别率关系曲线
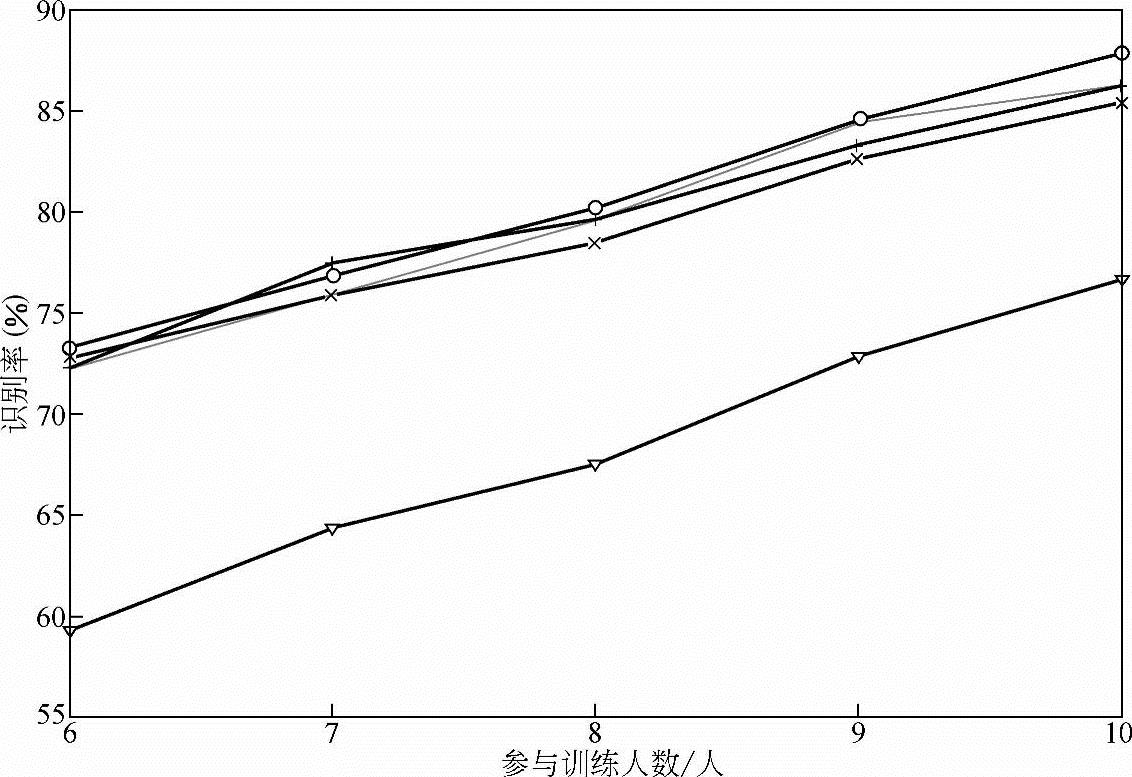
图10-30 基于非刚体光流法的表情特征提取下,参与训练人数与识别率关系曲线
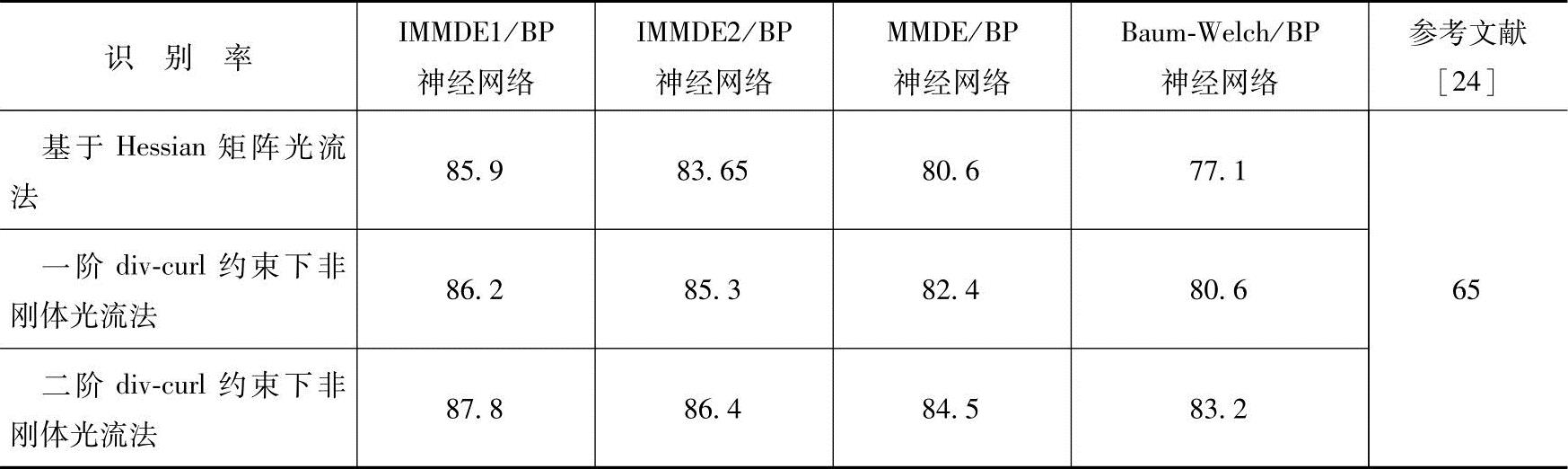
表10-7为各种方法在参与训练的人数为10时所有表情类的识别结果。同时引入参考文献[24]所述的作为对比。参考文献[24]提供的方法实质上是一种静态的表情识别方法,而本节所述的改进方法是一种动态表情识别方法,因此识别效果有明显提高。同时,采用的是改进的HMM训练方法,因此该方法较之其他动态方法(MMIE+BP神经网络和Baum-Welch+BP神经网络方法)也有一定改善。
表10-7 采用不同方法的面部表情识别结果比较 (%)
5.小结
本小节提出了一种基于改进MMD的HMM训练算法,并把它应用于面部表情识别中。该方法相对于传统算法,具有如下优点:
1)从表10-7可以看出,动态表情识别方法的识别率高于静态表情识别方法,这主要是因为动态识别方法提取表情图像变化的时间和空间信息,而静态识别方法只提取表情图像的空间信息,而忽略了表情图像变化的动态信息。
2)由于采用了改进的光流算法用于提取面部表情特征流,使得提取的表情运动信息更为准确,从而保证了识别效果的提高。
3)IMMDE1和IMMDE2训练算法充分利用了所有训练样本,在相同训练样本集下,采用改进MMD训练HMM得到的模型更为精确。
4)Baum-Welch训练算法只注重对本类样本的建模能力,忽略了对其他类样本的鉴别能力,如果出现与本类样本相似的其他类样本,则该HMM就很难对该样本作出准确分类。IMMDE方法引入最佳竞争模型集作为惩罚项,把提高模型鉴别能力作为模型参数优化目标,使得“己类模型输出概率最大,非己类模型输出概率最小”,因而可以大大提高识别能力;同时,由于MMD准则函数定义更为合理,使得系统识别结果较之原始MMD法有明显的改善。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。