



按功能此系统分为三部分:图像数据的采集和获取、数据的存取、人脸的检测和识别。前两部分都是依照设计部分来实现的,由于这两部分难度不大,主要是程序编写技术问题,这里就不再赘述。以下首先介绍OpenCV,然后讨论基于OpenCV的系统实现。
1.OpenCV简介
OpenCV是“Open Source Computer Vision Library”的简写,是Intel公司的开源计算机视觉库。它由一系列C函数和少量的C++类构成,实现了图像处理和计算机视觉方面的很多通用算法。在OpenCV最初的阶段,它是由美国Intel公司开发和维护的,随后Intel公司把它交给了开源社区维护和开发,经过全世界优秀的程序员的共同努力,现在的OpenCV已经演变成一个使用方便、功能强大、专注于计算机视觉方面的函数库,而且还在不断更新中。OpenCV的优点表现在以下几个方面:
● 开放源代码;
● 基于Intel处理器指令集开发的优化代码;
● 统一的结构和功能定义;
● 强大的图像和矩阵运算能力;
● 方便灵活的用户接口;
● 同时支持MS-Windows、Linux平台。
最新的OpenCV已经包含了大量的函数和例子用来处理计算机视觉领域中常见的问题,其中主要涉及到以下几个方面的内容:
● Motion Analysis and Objection Tracking(运动分析和目标跟踪);
● Image Analysis(图像分析);
● Structural Analysis(结构分析);
● Object Recognition(目标识别);
● 3D Reconstruction(三维重建)。
OpenCV的出现,给学习和开发带来了极大的方便。在研究和学习上,可以有更多的时间和精力来研究算法本身,而不是把大量的时间和精力花费在如何编程实现这个算法上,降低了系统实现难度。OpenCV在图像处理中有类似于MATLAB的封装功能,比如对于图像二值化操作,只需调用cvCvtColor(src,dst,CV_RGB2YCrCb)一个函数。在应用开发上,OpenCV为开发数字图像处理和计算机视觉领域的应用程序提供了功能完善、使用方便的接口,而且对应用开发无论是从商业用途还是非商业用途来说,OpenCV都是免费的,从而避免受版权问题的困扰。
2.基于Haar特征的人脸检测算法的实现
(1)分类器的训练
1)样本收集,包括非人脸图像和人脸图像的训练样本、非人脸和人脸的测试图像。非人脸图像的样本越多越好(5000~10000张),人脸图像6000张。并且对样本进行灰度化、归一化(20×20像素左右)处理。
2)确定弱分类器的θj等于该特征在所有样本上的特征值的和除以总样本数,表示一种平均的特征值。如果该样本在所有非人脸样本上的平均特征值大于在人脸样本上的平均特征值,那么pj取-1,反之取1。
3)确定强分类器的最大误检率fmax和最小检测率dmin,以及此强分类器的弱分类器个数。根据AdaBoost算法循环,每次添加一个弱分类器,同时修改权值。直至满足fmax和dmin。一般来说,强分类器的个数不少于20个。
4)构造层叠分类器,把拥有较高检测率的强分类器放在前几层,就能快速排除大量非人脸区域,加快检测速度。
OpenCV中提供了对特征和分类器的结构体定义,并且对最终的分类器格式也作了规定,存储成一个XML文件。我们最终训练的分类器只要满足OpenCV所要求的格式,那么就可以使用OpenCV提供的目标检测算法来检测人脸。
(2)基于OpenCV的人脸检测 在这个过程中,用到的就是OpenCV中的几个函数,其步骤是:为检测到的可能人脸区域分配内存,加载进入训练好的利用Haar的级联分类器,检测图像中的人脸,主要用到了以下三个函数:
1)storage_face=cvCreateMemStorage(0);//用于分配内存。
2)cvLoadHaarClassifierCascade//用于从文件中装载训练好的利用Haar特征的级联分类器,或者从OpenCV中嵌入的分类器数据库中导入。这个数值是在训练分类器时就确定好的,修改它并不能改变检测的范围或精度。
现在的目标检测分类器通常存储在XML文件中(OpenCV训练好的)。从文件中导入分类器,可以使用以下cvLoad函数:
cascade_face=(CvHaarClassifierCascade*)cvLoad("人脸模型\\haarcascade_frontalface_alt2.xml",0,0,0);
其中:
cascade_face:harr分类器级联的内部标识形式
Cascade:是结构体,结构是一个层次级联的形式,参见下面:
Stage1:
Classifier11:
Feature11
Classifier12:
Feature12
…
Stage2:
Classifier21:
Feature21
3)CvSeq*faces=cvHaarDetectObjects(small_img,cascade_face,storage_face,1.1,2,0,cvSize(50,50));
其中:
small_img:被检图像
cascade_face:函数2)中装载入的。
storage_face:函数1)申请的用来存储检测到的一序列候选目标矩形框的内存区域。
1.1为参数scale_factor的值,2为参数min_neighbors的值,0为参数flags的值。scale_factor:在前后两次相继的扫描中,搜索窗口的比例系数。例如1.1指将搜索窗口依次扩大10%。(https://www.xing528.com)
min_neighbors:构成检测目标的相邻矩形的最小个数(默认值为-1)。如果组成检测目标的小矩形的个数和小于min_neighbors-1都会被排除。如果min_neighbors为0,则函数不做任何操作就返回所有的被检候选矩形框,这种设定值一般用在用户自定义对检测结果的组合程序上。
flags:操作方式。当前唯一可以定义的操作方式是CV_HAAR_DO_CANNY_PRUNING。如果被设定,函数利用Canny边缘检测器来排除一些边缘很少或者很多的图像区域,因为这样的区域一般不含被检目标。人脸检测中通过设定阈值使用了这种方法,并因此提高了检测速度。
cvSize(50,50):设定参数min_size。
min_size:检测窗口的最小尺寸。默认的情况下被设为分类器训练时采用的样本尺寸(人脸检测中默认值是20×20)。
函数cvHaarDetectObjects使用针对某目标物体训练的级联分类器在图像中找到包含目标物体的矩形区域,并且将这些区域作为一序列的矩形框返回。函数以不同比例大小的扫描窗口对图像进行几次搜索(察看cvSetImagesForHaarClassifierCascade)。每次都要对图像中的这些重叠区域利用cvRunHaarClassifierCascade进行检测。有时候也会利用某些继承(Heuristics)技术,以减少分析的候选区域,例如利用Canny裁减(Prunning)方法。函数在处理和收集到候选的方框(全部通过级联分类器各层的区域)之后,接着对这些区域进行组合,并且返回一系列各个足够大的组合中的平均矩形。调节程序中的默认参数(scale_factor=1.1,min_neighbors=3,flags=0)用于对目标进行更精确同时也是耗时较长的进一步检测。为了能对视频图像进行更快的实时检测,参数设置通常是:scale_factor=1.2,min_neighbors=2,flags=CV_HAAR_DO_CANNY_PRUNING,min_size=<minimum possible face size>(例如,对于视频会议的图像区域)。
检测效果如图9-4所示。
实验证明,这种人脸检测的方法受光照的影响很小,不受类肤色模型的影响。
(3)人眼的检测 人脸检测之后,用和人脸检测相同的方法实现人眼的检测,在人眼检测时,为了实时性,我们也采用了相关的优化,根据人眼在人脸的位置特点,在左脸上半部分搜索左眼,在右脸上半部分搜索右眼,一开始我们是直接在整个人脸区域来搜索人眼,后来发现左右眼容易重叠,搜索易出错,然后才改进在左脸搜索左眼,在右脸搜索右眼,发现这样做识别效果很好。
左眼只在检测到的人脸图像的左半脸进行搜索和检测,右眼只在检测到的人脸图像的右半脸进行搜索和检测,这样加快了速度,并且杜绝了对复杂背景图像中类眼睛的误检测和左右眼的相互影响,通过以下的函数设置在左半脸感兴趣的区域:
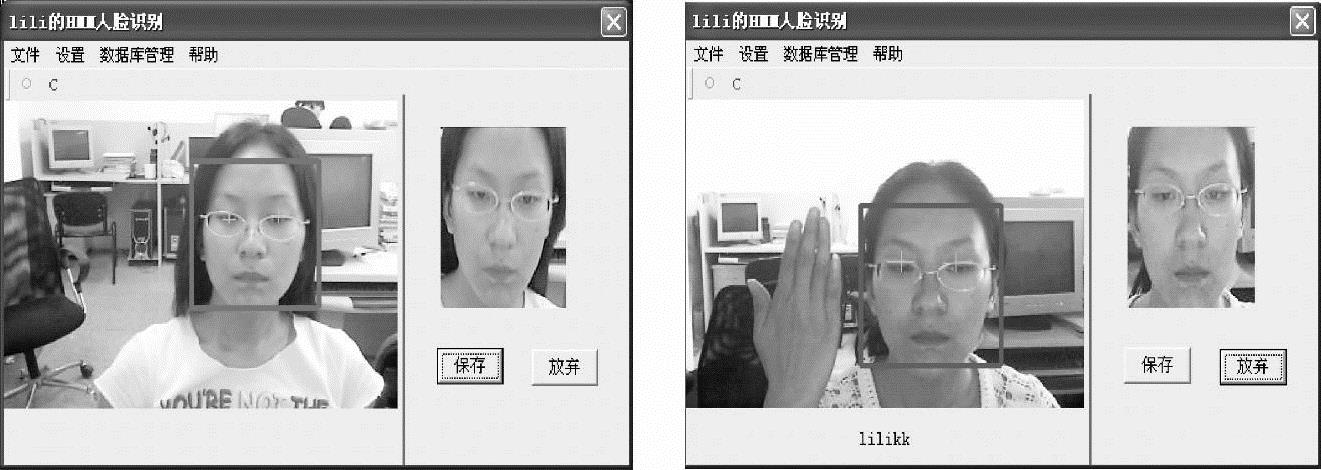
图9-4 系统最终效果图
cvCreateImage(cvSize(rect_face.width/2,rect_face.height/2),8,3);
cvSetImageROI(img,lr);
cvCopy(img,left_img);
在左半脸调用下面的函数检测左眼:
detect_and_draw_eye(left_img,rect_leye,cascade_leye,storage_leye);
检测右眼的方法和左眼的类似。人眼的检测效果如图9-4所示,其中十字交叉就是人眼的定位效果。
该系统中检测人眼的目的是为了人脸图像的自动采集,从而提高人脸识别系统的性能,当检测到人眼,并且左右眼基本水平时,就把当前帧图像采集下来,显示在人脸识别系统的右边,可以点击保存,存入数据库,对人脸表情有很大变化和脸部有遮挡物的图像,可以选择放弃。
3.基于EHMM的人脸识别算法的实现
(1)建立EHMM人脸模型 根据人脸的五官特征顺序,我们采用简化的EHMM来描述人脸,人脸的EHMM如图9-5所示,与一维隐马尔可夫模型相对应的五个状态变成超状态。超状态模型表示的是人脸的垂直方向上的图像信息,同时嵌入状态模型表示的是人脸水平方向的信息。超状态之间的转移关系按照从上向下在相邻两个超状态之间进行。
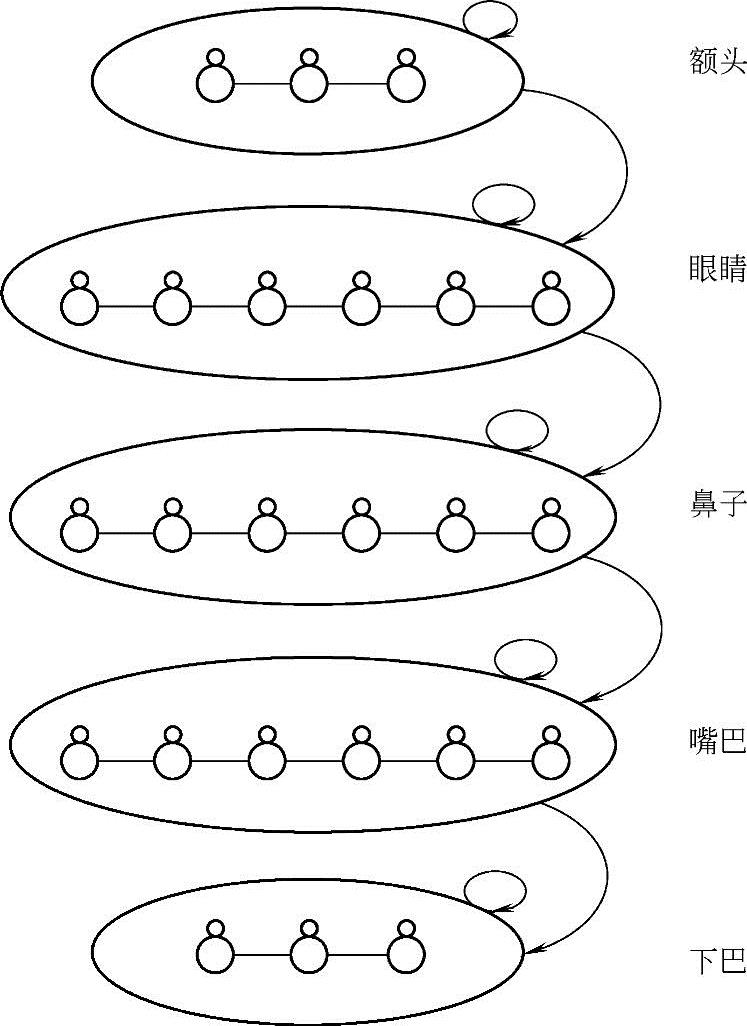
图9-5 人脸的EHMM
在进行EHMM人脸识别之前,从上到下的超状态数目选取、嵌入状态的状态数目选取、状态的转移概率矩阵选取以及由HMM产生的观察序列选取,对人脸识别是很必要的。该系统选定额头、眼睛、鼻子、嘴巴和下巴这五个显著区域隐含着的抽象状态来表示人脸从上到下的五个主要信息区域。嵌入状态的状态数选取主要考虑在给定的超状态中,从左到右想要得到的信息,嵌入状态的状态数分别为3、6、6、6、3,用来表示水平方向的抽象化状态。将这些状态数相加便得到共24个子状态。
确定了EHMM结构之后,下一个问题就是如何表示每个状态。实验中,每个状态的密度函数可采用包含一个或多个分量的混合高斯密度函数来表示。
(2)观察向量的提取 首先把人脸图像划分为图像块,形成图像块序列,然后取每一个图像块内像素点的灰度值或其变换系数组成一个观察向量,从而形成观察向量序列。该系统中,图像块采用遍历方法进行采样,就是在人脸图像平面上用一个大小为Lx×Ly的采样窗,从左到右、从上向下采样,相邻窗口在垂直方向和水平方向分别有Py行、Px列重叠,来获取观察图像块。
如果直接取采样窗内图像块的像素点灰度值构造观察向量,则存在下述问题:第一,观察向量维数太大,计算分析量太大:第二,像素灰度值对光照条件变化、视点变迁以及其他噪声干扰影响太敏感。该系统中,观察向量由图像块的二维离散余弦变换(2D-Discrete Cosine Transform,2D-DCT)系数构成,因为2D-DCT的结果是能量分布向低频成分集中,变换后能量集中在左上角,对应于2D-DCT低频系数,因此只取2D-DCT左上角的低频系数组成观察向量,就可以表示人脸的主要特征。由采样图像块的2D-DCT低频系数构造观察向量可以降低对噪声和光照变化的敏感度,受图像姿态的影响也较小,另外很重要一点就是减少了观察向量的维数,计算量大大降低了。
(3)EHMM的训练和人脸识别 EHMM的训练和人脸识别的流程是和HMM的基本相似的,现简单介绍其流程。
1)训练:人脸识别的EHMM训练用的是概率最大可能性评估标准,EHMM的训练与一维HMM训练的过程相类似,其目的就是要为每一个人确定一组经过优化了的EHMM参数。每个模型用多幅图像进行训练,可以表示一个人的多个版本,如不同的表情、姿态、有无戴眼镜等。训练的流程如图9-6所示,计算按以下步骤进行:
①预处理工作,包括几何尺寸归一化处理、灰度均衡等,形成训练图像。
②对人脸图像进行采样,并对每个采样窗进行2D-DCT,由2D-DCT系数构成观察向量序列。
③设定EHMM的超状态数和每一个超状态中嵌入子HMM的状态数。该系统超状态取5个,子状态序列取(3,6,6,6,3),共24个子状态。
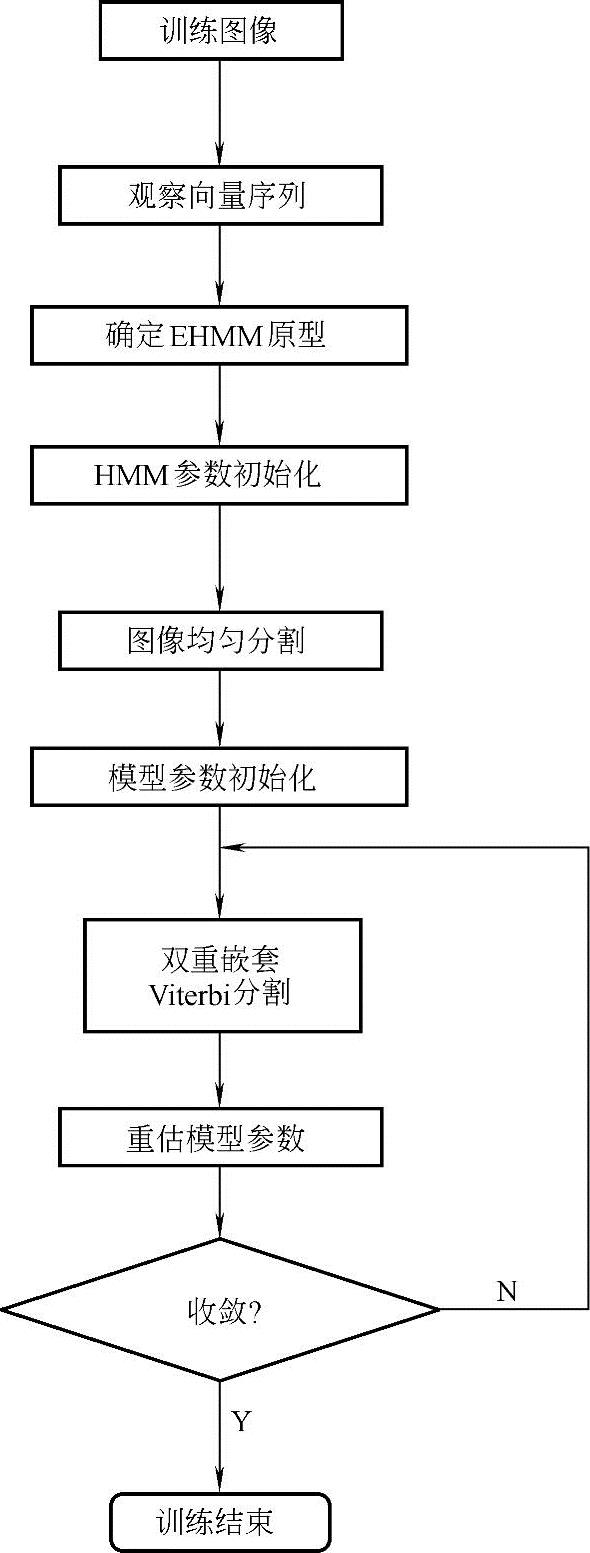
图9-6 EHMM训练流程
④根据超状态的个数和每个超状态内嵌入状态的个数以及模型的结构,将人脸均匀分割:首先,将人脸在垂直方向分割成N0个超状态;然后,将属于这个超状态的数据从左到右均匀分割成Nk1个嵌入状态,分别与子状态相对应。
⑤根据状态数和图像均匀分割后得到的观察向量,初始化EHMM参数。通过双重嵌套的Viterbi算法,对图像重新进行分割。
⑥用Baum-Welch算法重估模型参数。
⑦当前后两次的迭代误差小于某个阈值时,迭代停止,EHMM训练完毕。
对于连续隐马尔可夫模型,某个状态j的观察概率密度是由高斯概率密度函数的均值向量和方差向量来表征的。如果采用具有M个分量的混合高斯概率密度函数,则需要用K均值法将所有跟状态j有关的观测向量聚类M成类,每类分别求其均值和方差矩阵,作为各个高斯分量的均值和方差。采用混合高斯概率密度函数要优于采用单一高斯概率密度函数。
2)识别:人脸识别时,首先由待识别人脸图像构造观察向量序列,然后计算每一个训练模型产生该序列的最大似然值,具有最大似然值的模型即为待识别人脸图像所属对象。人脸识别流程如图9-7所示,可以用下列公式表示:
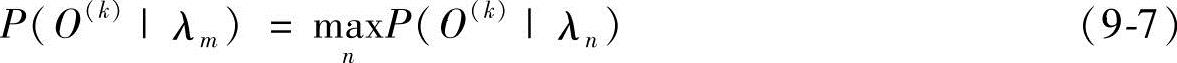
如果第m个模型λm产生序列O(k)的最大似然概率值取最大值,则将图像k归入第m类。
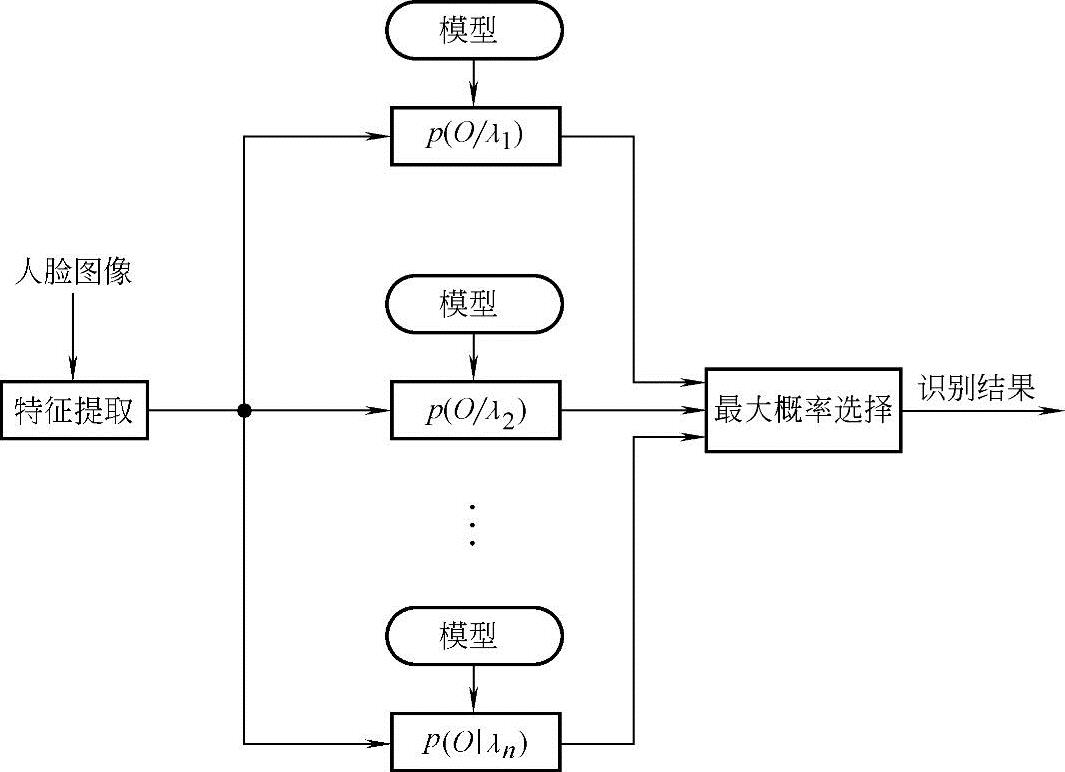
图9-7 EHMM人脸识别
最终的识别结果如图9-4所示。图9-4右边图片中,下方输出的字符串表示识别的结果,识别正确。在实验室条件下,采集10个人,每人10张人脸图像,每人每张图像的人脸旋转范围在5°之内,其中5张有中度的表情变化,该系统把每人的前5张图像作为样本进行训练,每人剩余的5张图像作为测试图像,识别48张正确,识别率达96%。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。