



在我们的人脸识别系统当中,主要包括两大部分,就是人脸检测和人脸识别。下面就分别对人脸检测和人脸识别的算法进行介绍。
1.基于Haar特征的人脸检测的算法
基于Haar特征的人脸检测方法的基本思想是:利用样本图像的Haar特征,基于AdaBoost分类算法,进行分类器训练。最后,组合几个简单的分类器得到最终的级联分类器。分类器训练完以后,就可以应用于输入图像中的感兴趣区域与训练样本相同的尺寸的检测。为了检测整幅图像,可以在图像中移动搜索窗口,检测每一个位置来确定可能的目标。为了搜索不同大小的目标物体,分类器被设计为可以进行尺寸改变的,这样比改变待检图像的尺寸大小更为有效。所以,为了在图像中检测未知大小的目标物体,扫描程序通常需要用不同比例大小的搜索窗口对图片进行几次扫描。在图像检测中,被检窗口依次通过每一级分类器,这样在前面几层的检测中,大部分的候选区域就被排除了,全部通过每一级分类器检测的区域即为目标区域。
(1)AdaBoost学习算法 对于Haar特征而言,一个24×24像素的矩形区域可以形成的Haar矩形特征达几万种,远远超过了24×24的像素的个数。即使每个特征都可以快速地计算,计算所有的集合都非常耗时。我们可以首先假设,一个很小的特征集合就可以组合成有效的分类器(后来的试验证实了这一个假设)。但是,最大的挑战就是如何选择这些特征。
在给定正例图像和反例图像作为训练图像集合后,再针对某个特定的特征集合,可以通过任何机器学习方法(例如:混合高斯模型、神经系统等)来训练。最近机器学习研究提出的支持向量机和放大(Boost)方法,都可以在非常高维的空间中进行分类。我们使用后者,因为它可以在许多可能的特征中选择很少一部分。放大(Boost)算法中,所谓的“弱学习器”(Weak Learner),就是指那些简单的学习算法。我们不期望最好的分类函数来对训练数据分类,例如最好的感知器也只能对训练集合达到91%的分类。为了使得弱分类的增强放大,需要进行一系列的学习。对第一轮学习后,样本被重新计算权值,增强那些非正确分类部分。最后,一个“强分类器”就形成了,它是弱分类器在取某个阈值后的加权组合。例如,对于“简单感知器”而言,最终的“强分类器”就是“简单感知器”的加权组合,也就是说,一个简单的、数量很少的弱分类器可以进行组合成为强分类器。
AdaBoost学习算法的学习过程,可以理解为“贪婪的特征选择过程”。对一个问题,通过加权投票机制,用大量的分类函数的加权组合来判断。算法的关键是,将那些分类效果好的分类函数赋予大的权值,分类效果差的赋予较小的权值。AdaBoost是一个寻找那些可以对目标很好地进行分类的少数特征的有效方法。
实际应用中,使用AdaBoost的方法选择特征,就是将“弱学习器”加上一个限定,一个“弱学习器”对应一个矩形特征,在进行放大(Boost)的过程中,每一次放大选择一个学习器,就是选择一个特征。这个学习器对正例和反例的区分度达到最优。对每个特征,“弱学习器”使得每个分类函数的阈值达到最优。在这里的弱分类器指的是用Haar特征直接构成的分类器,弱分类器的函数表达式如下:
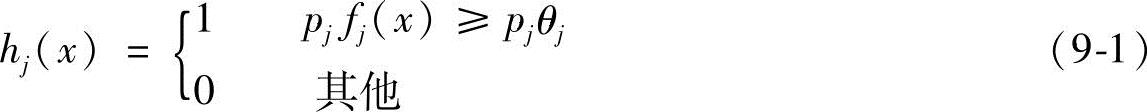
式中,x表示任意输入窗口;fj(x)表示第j个特征在x上的值;pj取值+1、-1控制不等式方向;θj表示阈值。弱分类器所含信息量较少,不能用来直接分类。单一的特征无法保证分类达到很低的误差。在早一轮的选择特征的错误率可以在0.1~0.3之间,而随着后一轮的放大,误差会增大,在0.4~0.5之间。
下面是学习算法(T为特征个数):
1)对样本(x1,y1),…,(xn,yn)yi=1表示图像是正比例,yi=0表示图像是反比例。
2)初始化权值W1,i

3)t=1
4)将权值归一化

5)对每个特征j,训练一个只使用某一个单一特征的分类器hj,然后得到本次分类的误差ej为

6)选择误差ej最小的分类器ht,更新权值: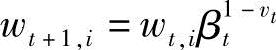 :①当xi分类正确时,vt=0;②当xi分类错误时,vt=1,βt=et/(1-et)。
:①当xi分类正确时,vt=0;②当xi分类错误时,vt=1,βt=et/(1-et)。
7)t=t+1
8)t<T转向4)
9)得到最后的分类器。
1988年,Kearns等人提出了Boosting理论基本思想:在机器学习中,“弱的学习算法”可以应用一定的策略进行加强,从而得到任意精确的“强的学习算法”。1997年Freund等人提出自适应增强(Adaptive Boosting)算法。这种方法允许分类器设计者不断加入新的“弱分类器”,直到达到预设的分类精度。此算法训练过程中,每个样本拥有一个初始权值,表示该样本被某个弱分类器选中的概率。如果某个样本被正确分类,构造下一个训练集时,降低其权值,反之增加其权值。通过此算法,每一轮都会增强那些使分类错误的“困难”样本上,每一轮选出一个最优弱分类器,这些分类器线性组合而成强分类器,即
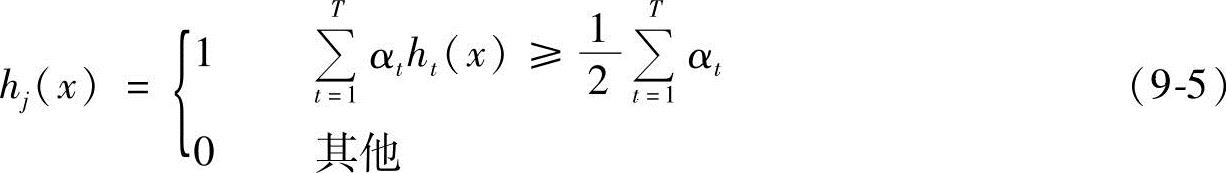
式中,αt=log(1/βt),βi表示第i迭代时hi(x)的权值。
最后,AdaBoost算法构造的特征大概为200个。对于人脸检测,AdaBoost选择的权值最高的几个矩形特征很容易理解。第一个特征关注的,就是包含眼睛的区域。眼睛区域比鼻子和面颊的矩形区域亮度上更暗(亮度值小于某个阈值)。这个特征是和人脸大小以及位置无关。第二个特征表示的,是眼睛所在的区域总是比鼻梁所在的区域亮度更暗,所以通过选择和学习后的包含200个特征的分类器,对于目标检测是非常有效的。(https://www.xing528.com)
(2)层叠分类器算法 对于多个强分类器,采用排除的思想,即先用比较简单的特征构成的强分类器去排除显然不是人脸的区域,然后把剩余的待检测区域送到下一个强分类器进行处理,这样逐级排除,最终排除了所有非人脸区域。如果有剩余区域,那就是人脸区域,否则表示未检测到人脸区域。对于有K个强分器构成的层叠分类器,其检测率F和误检率D分别如下列两式所示:

从以上两个公式可以得出两点结论:
1)为了保证最终的高检测率,每个强分类器也要求有高检测率。假设最终的检测率是90%,那么对于每一个强分类器,其检测率都不能低于90%,如果K=10,那么每个强分类器的检测率都应该在99%左右,因为0.9910≈0.9。检测率高只是保证如果有人脸,必然能检测出,但不保证把非人脸检测为人脸的误检。
2)为了降低最终的误检率,不必过分强求每一个强分类器有很低的误检率。假设每个强分类器的误检率为0.5。对于K=10的层叠分类器最终的误检率=0.510≈0.1%。
(3)视频序列中减少检测区域的算法设计 经过测试,发现在背景不是很复杂且相对静止的情况下,人脸正面左右偏头不超过20°时,检测率能达到98%,并且误检率几乎为0。
经过测试,对于常见视频320×240像素大小的图片,需要56ms左右,常见视频的帧率是24~30帧/s,也就是说每帧时长为33~42ms,如果要做到实时人脸检测,算法耗时最好少于20ms,因为要为系统的后续处理(比如人脸识别和表情识别)留下足够的处理时间。
1)图像大小的耗时测试:对大量相同图像进行尺度上的缩放,并且用训练好的Haar分类器进行了测试。表9-1所示是图像处理的经典图片lena.jpg的耗时(不包括图像读取和格式转换的时间)。
表9-1 相同图像内容、不同图像大小人脸检测耗时

由上面的实验可以得出的结论是:基于Haar特征的人脸检测耗时跟图像大小成正比。这也很容易理解,图像面积越大,需要计算的弱分类器中的特征值就越多,导致耗时增加。
2)最小人脸尺度区域的耗时测试:因为人脸大小未知,所以需要多尺度搜索,给定一个最小搜索尺度,如果为20×20像素,那么每检测一次尺度都变为上次1.2倍(可以自定义,一般为这个值),即检测区域大小为(20×1.2i)×(20×1.2i),其中i表示第几次,当然要限制此区域长宽都不能超过图像长宽。对于视频图像大小320×240像素,我们得到表9-2所示的测试结果。
表9-2 相同图像不同最小人脸检测尺度耗时

由上面的实验我们得出的结论是:基于Haar特征的人脸检测耗时跟检测最小人脸尺度成反比。因为人脸尺度未知,那么需要多尺度检测,最小人脸尺度越大,尺度层次就越少,时间也就越少。
经过以上的实验,为了显著降低Haar特征提取耗时,必须减少待检测区域,增加最小人脸尺度区域。众所周知,视频序列图像中两帧图像之间有很大的相关性,可以利用时序序列图像的相关性,减小待检测区域,增加最小人脸尺度区域。以下讨论基于Haar特征的人脸检测算法在视频序列图像中的改进方法。假设已知所检测的视频中最多有一个人脸,我们提出如下的检测步骤:
①如果是第一帧图像或者前一帧没有找到人脸,执行步骤③。否则做如下处理:对后续的视频图像序列,在前一帧人脸区域的1.2倍区域寻找人脸,且将最小人脸尺度设置为前一帧人脸尺度的0.8倍,例如前一帧的人脸尺度为100×100像素,那么此帧的人脸尺度为(100×0.8)×(100×0.8)像素。如果检测到人脸,则此帧处理完毕。
②参考文献[5]讨论了一种车体识别方法,计算此帧灰度图像和前一帧图像的灰度值差,然后对差分图像进行自适应阈值的二值化,计算投影来判定汽车位置。我们把这种算法进行改进并应用到人脸检测上。如图9-3所示,最上面两幅是视频序列图像中的两帧连续的图像,下面左边图示的是对差分图像进行自适应阈值的二值化图像。最后进行水平和垂直投影得到变化区域,在此区域的1.2倍区域内检测人脸,最小人脸尺度设置此区域的0.8倍,如果检测到人脸,则此帧处理完毕。对于大小为320×240像素的视频序列图像,经实验测试,此步骤处理平均耗时平均仅为4ms。
③在全图像中寻找人脸,最小人脸搜索尺度设置为20×20像素。如果检测到人脸,那么此帧处理完毕,否则认为此帧图像无人脸。

图9-3 差分检测人脸
在上述的检测步骤中,其实是对应人脸在视频中的三种情况:一、被检测的人脸在摄像头的视频范围内没有大的移动,相当于有一种先验知识,减小了待检测区域,采用步骤①就可以检测到人脸;二、被检测的人脸有移动,采用步骤②的差分方法估计移动区域,减少了待检测区域,用Haar特征算法可以很快地检测到人脸,提高了实时性;三、移动范围过大甚至移出摄像区域,那么执行步骤③确定是否有人脸。这些步骤虽然看似比直接从全图像寻找人脸复杂,但是对于视频序列的人脸检测,却能显著提高检测速度,如果有人脸存在,那么在视频序列中人脸图像的位置和尺度会有很大的相关性,根据前几帧的先验知识,限定检测区域和人脸搜索尺度区域的大小,可以显著地提高算法效率和实时性。
2.人脸识别的HMM算法
对于已检测出的人脸图像,将它与数据库中的已知人脸进行比较匹配,得出识别的结果。这部分工作是由人脸识别算法来完成。对于自动人脸识别系统,一个环境适应性强并且识别率高的算法是整个系统的关键。人脸识别部分采用了一种较为成熟的人脸识别方法——基于隐马尔可夫模型(HMM)的人脸识别方法。关于隐马尔可夫模型的介绍可参考本书的第8章。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。