



特定人脸建模是指利用具体人脸信息建立个性化的人脸模型,用以描述不同人的具体特征。按照模型的产生方式可以把构造个性化人脸模型的方法分成两类:一类是根据已知具体人脸的三维信息直接构造三维模型的方法,如基于扫描仪、数字化探针、立体相机和基于计算机视觉的方法(如光流技术和结构光方法);另一类是对一般模型进行拟合和变形建立个性化特定人脸模型的方法,如基于正交照片的三维重建。前者往往根据具体数据采用插值、曲面优化等技术达到建模的目的,通常对数据的要求比较苛刻,如要求数据点分布均匀且噪声较小,但建成后的模型缺乏结构信息。后者将标准人脸模型作为先验知识,通过刚体变换、形变等手段与具体的人脸数据拟合达到形状匹配,并且利用图像合成面部纹理信息从而建立逼真的三维个性模型。
1.直接构造特定人脸三维模型的方法
直接构造特定人脸三维模型的方法一般有图8-2所示的流程。
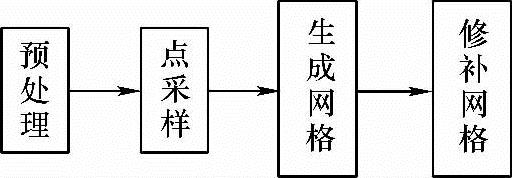
图8-2 直接构造特定人脸三维模型的流程
直接构造特定人脸三维模型的方法除了有8.3.2节介绍的方法外,还有基于立体照相机和计算机视觉的方法。立体照相机这样的距离测试方法能在某些特征点处建立对应关系。该方法使用立体图像之间的几何关系回复曲面的深度。Turing学院的C3D 2020捕捉系统曾用立体照相镜的方法产生了许多虚拟现实建模语言(VRML)模型。计算机视觉是年轻的仍在发展的科学。根据三维视觉、几何和辐射学方面的研究成果,人们可以从对应点计算、多个相机组合、物体的轮廓和表面反射等方法来获取人脸模型。
用这种方法构造的模型因为没有人脸结构的信息,通常不适合脸部动画,且数据带有噪声、顶点分布不合理。
2.对一般模型进行拟合和变形建立特定人脸模型的方法
这类方法的一般流程如图8-3所示。
从一般模型建立个性化模型的方法是,首先准备一个原形或通用动画网格,它带有所必需的结构和动画信息。然后将该模型拟合或变形到测量出的特定人脸的几何网格上,从而创建出个性化的动画模型。当通用模型的多边形网格数比测量出的网格数少时,拟合过程也暗含了对测量数据的抽取。特定人脸的造型和拟合过程可以使用不同的方法,如散乱数据的插值、人类学技术和结合了正拉普拉斯场函数的向柱面坐标投影的技术。有些方法尝试了自动的拟合过程,但大多数方法需大量的手工交互。
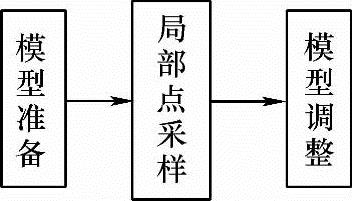
图8-3 对一般模型进行拟合和变形建立特定 人脸模型的流程(https://www.xing528.com)
(1)双线性插值 Parke使用了双线性插值来创建不同的人脸外形[10]。他假定大多数人脸类型可以用一个拓扑结构的不同变化来表示。他通过改变通用人脸的构造参数创建了10个不同的人脸。Parke的参数化模型受限于所给定的构造参数的范围,而且在一张特定人脸上调节参数是很困难的。
(2)散乱数据插值 径向基函数能通过相对较少的点和插值来获得光滑的人脸曲面。有些造型方法使用基于径向基函数的散乱数据插值技术,将一个通用网格变形成特定形状。这种方法的优点是:变形不需要与目标网格相同的顶点数,这是因为缺少的顶点可通过插值得到,只要选择恰当的对应关系,就能从理论上保证被变形网格接近目标网格。
Ulgen使用了三维体变形获得从通用人脸模型到目标模型的光滑过渡[11]。该算法首先在两个模型的眼睛、鼻子、嘴唇和轮廓上选择一些具有生物意义的标识。这些标识的选择应该易于标注且位置相对容易确定。然后,利用这些标识点计算出用于体变形的Hardy多二次曲面(Multi-quadric)径向基函数的系数。最后,根据由标识点计算得到的这些系数,插值得到通用网格上的其他点的位置。例如:一个通用模型使用了1251个多边形,而目标模型具有1157个多边形。150个标志顶点被手工标注,其中50个在鼻子附近。显然,变形成功与否很大程度上依赖于标识点的数量和位置。
Pighin等人采用的散乱数据插值技术的拟合过程[12]分三步:第一步,估计摄像机参数(位置、方向和焦距),这些参数与手工选择的对应点相结合产生脸上特征点的三维坐标;第二步,根据特征点的三维坐标确定用于变形的径向基函数的系数;第三步,用辅助的对应关系进行微调。一个少于400个多边形的通用网格用初始的13个对应点变形,最后是99个点用于微调。
(3)自动建立对应点 根据拟合的原理,在拟合时需要建立源和目标模型之间的精确对应关系,不正确或不完整的对应关系将导致很差的拟合结果。手工选择对应关系能够建立比较精确的对应关系,但是这是一项艰辛的工作,而且误差积累会越来越大。也有几个图像处理的方法使用已知的人脸属性尝试自动建立对应点,从而实现自动适配。
Lee等人,给出一个基于激光扫描的深度和反射数据自动构造个性化人脸模型的方法。为了获取更可靠的自动检测人脸特征,Lee率先在深度图上使用拉普拉斯算子,并获得拉普拉斯场图。拉普拉斯场图上的网格适配过程可以自动确定特征点。预先标注了特征的通用模型通过启发式网格适配过程被对应到三维网格几何模型和纹理上。
(4)人体测量学 在获取个性化的人头模型时,由于激光扫描和立体图像能分别获得几何细节和细腻的纹理,所以被广泛使用。然而,正如前面所述,这些方法也有缺点。扫描数据或立体图像经常由于遮挡而漏掉某些区域。因此,必须根据情况手工修补模型。现有的自动对应点匹配方法还不够鲁棒,若特征点在测得的数据上不明显,则仍需手工调节。
在人脸变化理想而且不需要精确的外貌的领域,人们使用基于人体测量学的个性化模型生成方法解决了上述问题。Kuo等人给出了从一张没有深度信息的正面二维灰度图合成侧面人脸的方法。该算法首先需要建立根据人体测量学的定义测得的人脸参数的数据库,并以这个数据库作为先验知识。其次,通过将基于最小均方差(MMSE)的估计规则应用于上述数据库,就可以从正面的人脸参数估计出侧面人脸的参数。侧面人脸参数的深度可以通过几个正面的人脸参数线性组合得到。有了从照片中抽取的正面坐标和深度估值,就可以调整通用的三维人脸模型,并且可以根据特征数据和纹理映射合成侧面人脸。
虽然Kuo仅使用一张正面图像的人体测量就实现了个性模型重建,但Decarlo等人更是实现了基于无图像辅助的人体测量学构造不同人脸模型的方法。该系统分两步构造一张新的人脸模型。第一步,产生一个代表特定人脸测量数据的随机集。这些测量数据的形式和数值是参照人脸的人体测量学计算出来的。第二步,用变分约束优化技术构造满足几何约束的最优曲面。在该技术中,一般在曲面上加入多种约束,并在这些约束条件下,尝试构造与原始形状偏差最小化的光滑曲面。在参考文献[16]中,以人体测量学的尺度为约束,最小化与给定曲面的目标方程的偏差来决定人脸的其他部分。不同的模型能使系统捕捉人脸形状的相似性,又能允许出现人体测量的差异。尽管人体测量学方法在快速创建出令人满意的多变的人脸几何方面具有优势,但它不能再现颜色、皱纹、表情和头发方面的真实变化。
(5)其他方法 Essa等人用标准特征空间(Modular Eigenspace)方法处理拟合问题。这种方法能在图像上自动抽取眼睛、鼻子和嘴唇等特征点的位置。这些特征定义了使特定人脸图像与通用人脸模型相匹配的图像变形。图像变形后,从图像中抽取出可变形顶点用于进一步的细化。Dipaola的人脸动画系统(FAS)是对Parke方法的扩展。它通过将活体或雕塑数字化或用自由变形、随机噪声变形或定点编辑来操作已有的模型,从而产生新的人脸模型。
从一般人脸中性模型到特定人脸中性模型的修改过程中,要进行两种变换:首先要对一般人脸模型进行整体变换,整体变换的目的是完成面部整体轮廓的修改,使其与特定人脸的脸形和五官的大致位置相匹配;然后在对整体变换后的人脸中性模型进行局部变换,目的是根据特定人脸的眉、眼、口、鼻的形状和大小进行修改,即在一般人脸中性模型上打上特定人脸特征的烙印。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。