



对于人脸合成的相关技术有不同的分类方式,这里采用以几何处理和图像处理为基础的分类方式。图8-1所示是按照这种分类方式对人脸建模和人脸动画驱动进行分类的框图。
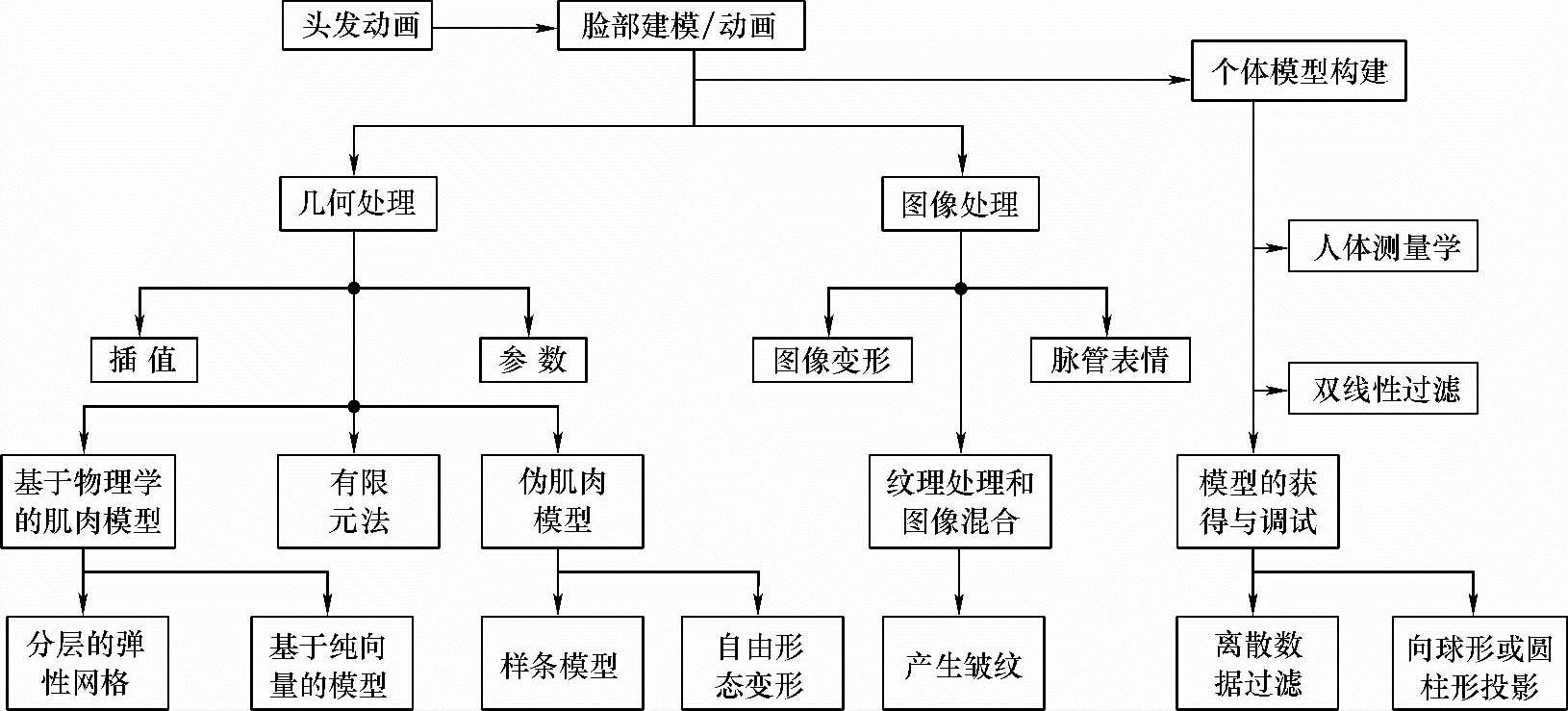
图8-1 人脸合成方法分类框图
基于几何处理的方法包括插值法、参数化法、有限元法、基于物理学的肌肉模型法、伪肌肉模型法等。基于图像处理的方法主要可以分为如下几类:二维与三维图像变形、脉管表情、纹理处理和图像混合等法。
1.基于几何处理的方法
(1)插值法 插值法提供了一种直观的实现人脸合成的方法。典型的是,一个插值函数确定了单位时间间隔内相邻两个关键帧之间的平滑过渡。插值函数可以根据需要选取,如线性插值、余弦插值、径向基函数插值。通过改变插值函数的参数可以生成不同的插值图像。几何插值方法可以直接控制网格来改变脸部网格顶点的坐标,而参数插值法能够通过改变函数参数和函数本身间接地移动网格点。尽管插值运算简单且速度非常快,而且容易生成原始的人脸表情,但是由于它表现能力的限制和人脸的复杂性,使用它创建大范围具有真实感的人脸表情状态空间的能力有限,并且该方法很难将相互没有关联的人脸关键帧进行插值组合,但在需要基于少数关键帧产生一组连续动画时,插值法仍然不失为一个好方法。
(2)参数化法 参数化技术克服了简单插值的一些局限性。理想情况下,参数化技术通过组合一些独立的参数值可以生成任何可能的人脸表情。与插值技术不同,参数化允许直接控制特定的表情配置(Facial Configuration),而且经过少量的计算,就可以通过组合参数来获得各种丰富的人脸表情,通过设定参数作用区,还可以减少计算工作量。但是,由于人脸的复杂性,很难设计完全相互独立的参数,当用对同一个顶点都起作用但有冲突的两个参数区获得调和表情时,并没有一种系统的手段来仲裁该如何选取这两个相互冲突的参数,故而参数间存在冲突时,参数化方法通常只能产生不自然的人脸表情或外形。为此,人们只在特定的脸部区域使用参数化方法,以避免产生相互冲突的参数,但这样又会在脸部造成明显的运动边界。参数化方法的另外一个局限是参数集的选择依赖于人脸网格的拓扑结构,因此一个完全通用的参数化是不可能有的。在具有不同的拓扑结构上使用参数集需要增加模型的适配过程,这不仅影响了模型的通用性,而且为了设定最佳的参数值,需要大量的人工调整,尽管如此,也可能产生不真实的运动或形状。
(3)基于物理学的肌肉模型法 基于物理学的肌肉模型可以分为三类:质点弹簧(Mass Spring)模型、向量表示模型和分层弹性网格模型。质点弹簧法在一个弹性网格中传播肌肉拉力,从而导致肌肉的变形。向量肌肉法在影响区域内用运动场的形式来对脸部网格变形。分层弹性网格法则是将一个质点弹簧结构扩展为三个相连的网格层,从而更逼真地模拟真实人脸的物理行为。
1)质点弹簧法:在弹簧网中传播肌肉作用力,以对皮肤变形建模。通过肌肉弧将力作用在弹性网格上,以生成人脸表情。
2)向量肌肉法:该方法通过一个描述型的变形场来对肌肉动作对皮肤的作用进行建模,其基本思想是将特定的肌肉参数值赋予脸部肌肉模型。这些参数仅是一种抽象,并不用来模拟生理学或心理学的机制。不同人脸的网格顶点或控制顶点由附在这些点上的参数肌肉模型所控制,脸部的拓扑结构在运动中保持不变,肌肉的运动仅限于变形区域,肌肉被定义成向量的形式,包含原点和插入点。其作用范围由余弦函数和衰减因子定义。当作用范围被可视化为一个高度场时,余弦函数和衰减因子产生一个圆锥的形状。然而由于人脸结构的不确定性,按解剖学结构正确地放置向量肌肉是非常困难的,至今还没有一个能够将向量肌肉自动放置到人脸网格中的方法,整个过程需要手工试验,而且不能保证结果是有效的和最优的。尽管放置不正确的向量肌肉会导致不自然的甚至是奇怪的表情动画,但是这种模型的表现形式非常紧凑,而且独立于人脸网格的结构,所以该模型目前得到广泛的使用。
3)分层弹性网格法:Terzopoulos和Waters给出了能模拟细微解剖结构的人脸模型和动态人脸。可变形网格包含三层:皮肤、脂肪组织和附于骨头的肌肉层。具有弹性的弹簧元素连接每个网格节点和每一层。肌肉拉力通过弹性网格的传播产生脸部表情。这种建模方法具有很强的真实感。但是使用三维网格模拟体变形需要巨大的计算开销。
(4)有限元法 有限元法是一种逼近任意复杂物体物理特性的数值方法。一个物体被分解为区域或者体元素,每个元素都被赋予物理参数。元素间的动态关系是通过将分段的组成部分整合到整个物体中得到的。这种方法是计算非常密集的方法。
(5)伪肌肉模型法(模拟肌肉法) 通过建模逼近人的解剖结构,以产生真实感的结果。肌肉的作用力是通过样条、线或者自由变形(Free Form Deformation,FFD)模型得到的。(https://www.xing528.com)
1)自由变形模型:通过操纵分布在一个三维网格上的控制点来对体对象进行变形。FFD可以使多种类型的表面图元变形,包括多边形、二次、参数和隐含曲面,以及实体模型。另一种方法是有理自由变形(Rational FFD,RFFD),包括了每一个控制点的权重。Dirichlet自由变形(DFFD)是另一种自由变形的方法。
2)样条模型:支持平滑和灵活的变形,允许曲面的局部变形,减少了计算复杂度。
3)线模型:一组域曲线构成了一个隐含的建模图元。
2.基于图像处理的方法
(1)二维与三维图像变形 二维图像的变形由目标图像中对应点的集合和一个并发的淡进淡出构成。典型的是,对应关系是人工指定的。二维与三维方法可以生成真实的人脸表情,但是它们也具有与插值方法类似的局限性。
(2)脉管表情 真实的人脸建模和动画不仅需要人脸的变形,而且需要随人的情感状态不同而呈现出皮肤颜色的变化。可以通过在发生强烈情感时相应改变所有面片的颜色或通过纹理映射来达到这个目标,在这个方面的研究不是很多。
(3)模型匹配 将一个预先定义好的模型匹配到人脸图像上。人脸模型可以具有任意精度,但是通常只能定位出人脸的一个大致轮廓和一些人脸特征运动。Ahlberg描述了一个基于图像的人脸模型匹配算法。
(4)基于跟踪的表情映射 使用其他方法来获得像真人一样的人脸表情有各种各样的困难。因而产生了一种基于表演驱动(Performance Driven)的方法,使用跟踪演员得到的运动来控制角色的表情。实时的视频处理允许交互的动画得以生成,演员可以实时地看到他们创造的运动和表情。准确地跟踪人脸特征和边缘对保持表情的移植性和真实感非常重要。
另一种分类方式是将人脸合成技术分成基于模型的方法和基于图像库的方法。在近30年的时间里,传统的人脸合成方法都是基于三维物体来进行建模的。在基于模型的方法中,需要定义模型控制参数,利用几何、声学或者肌肉模型来使三维结构发生变化。目前用在人脸合成系统中的大部分模型都是派生于Parke等人的模型,控制参数通过几何函数来移动脸部顶点。一些基本的操作在脸部区域中逐渐变小,然后融入周围地区。区域之间的内插用来产生表情或者改变形状。每一个区域都是独立受控于极端形状之间,并且与某个参数相联系。控制参数可以是某个点的三维坐标,比如嘴角,也可以是驱动复杂的变形。这样的合成机制成为MPEG-4的标准。基于模型的方法能够灵活地对模型进行控制,模型可以做出包括真实人脸没有办法做出的几乎各种动作,在处理速度上也比较快,但是在真实感上有较大的差异,容易产生“人造”的感觉,这是由真实人脸的复杂度和精细度决定的。另一种人脸合成方法是基于图像库的方法,对基于模型的方法发起了挑战。这种方法类似于大语料库语音合成技术,只是处理的对象不是语音而主要是图像。这种方法的基本处理步骤是:从一个事先建立好的真人图像库中根据一定的规则挑选视频片断,然后做相关的图像处理,最后进行拼接,从而达到合成的目的。这种方法思想简单,合成人脸的逼真程度和真人没有任何区别,但是建立合适、紧凑的高质量的图像库却并非易事,而且此方法只能够合成图像库中已有的人脸姿态和表情,以及这些表情的插值表情,在处理速度上难以达到实时要求。
总的来说,人脸合成主要分为两个部分:人脸建模和人脸动画。人脸建模主要研究人脸模型的静态建模,合成人脸模型的几何外形特征和纹理特征。其中,既包含了如何合成同一个人脸模型在不同的表情和动作状态下形状和纹理特征,也包含了如何合成不同人脸模型的形状和纹理特征。人脸动画主要研究人脸的动态过程,研究人脸在运动和做表情时人脸外形和纹理的动态变化过程,及如何合成具有真实感的人脸动画序列。
本章根据人脸合成的流程顺序来介绍在人脸合成中常用的方法与技术。首先是人脸建模,包括一般人脸模型和特定人脸模型的构建,以及纹理贴图;然后是人脸动画,包括人脸运动和表情的合成。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。