



Fisher判别是一种应用得极为广泛的线性分类方法,其基本思想是:把d维空间的所有模式投影到一条过原点的直线上,即将模式的维数压缩到一维,并要求同一类型的样本尽可能聚在一起,不同类型的样本尽可能地分开。
Fisher线性判别分析(Fisher Discriminant Analysis,FDA)算法是R.A.Fisher于1936年提出的一种旨在降低特征维数的方法。FDA算法是有监督学习算法,其目标是找到线性投影方向(投影轴)使得训练样本在这些轴上的投影结果为:类内散度最小,类间散度最大。换句话说,FDA算法建立了一个子空间(由所有的投影轴构成),所有样本在这个子空间内满足类内散度最小、类间散度最大等要求。所有样本在这些投影轴上的投影系数可以作为样本的特征向量,利用这些特征向量,就可以进行样本的分类识别。
1.两类问题
先讨论简单的两类Fisher线性判别分析。
假设有一组n个d维的样本X1,X2,…,Xn,它们分属于两个不同的类别,其中大小为n1的样本子集D1属于类别ω1,大小为n2的样本子集D2属于类别ω2。如果对X中的各个成分作线性组合,就得到点积,结果是一个标量
y=WTX (7-5)
其中,W=(w1,w2,…,wn)是线性组合的权重。
这样,全部的n个样本X1,X2,…,Xn就产生了n个结果y1,y2,…,yn,相应地属于集合Y1,Y2。从几何上说,如果||W||=1,那么每个yi就是把Xi向方向为W的直线进行投影的结果,W的幅值不重要,重要的是其方向。因为,向不同方向的直线作投影,其产生的结果在可分程度上是非常不同的。如果属于类别ω1的样本和属于类别ω2的样本在d维空间中分别形成两个显著分开的聚类,那么希望投影后也尽量地分开。只有确定了最佳的直线方向,才能达到最好的分类效果。由此也可知道,如果各个类别的样本在原始的d维空间就是不可分的,那么无论向什么方向投影都无法产生可分的结果,因此也就不适合用线性判别分析。
下面讨论如何确定最佳的直线方向W。一个用来衡量投影结果的分量程度的度量是样本均值的差。如果ui为第i类的d维样本均值,则有

则投影后点的样本均值为
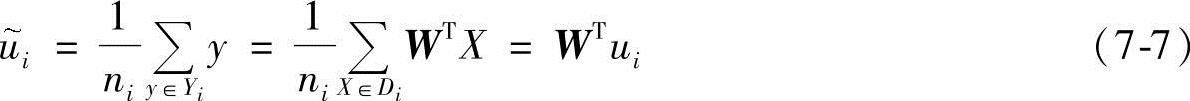
也正好是原样本均值ui的投影,则投影后的点的两类样本均值差为

由此可见,通过改变W的幅值,可以得到任意大小的投影样本均值差。但是两类数据的投影样本均值差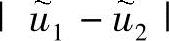 的大小并不能完全体现两类数据的可分性,如图7-1所示。当投影到x轴时,投影样本均值差要大于投影到y轴的投影样本均值差,但是投影到x轴的数据可分性却明显次于投影到y轴的可分性。因此,还需要定义类内散布
的大小并不能完全体现两类数据的可分性,如图7-1所示。当投影到x轴时,投影样本均值差要大于投影到y轴的投影样本均值差,但是投影到x轴的数据可分性却明显次于投影到y轴的可分性。因此,还需要定义类内散布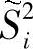 。对类别ωi的类内散布定义如下:
。对类别ωi的类内散布定义如下:

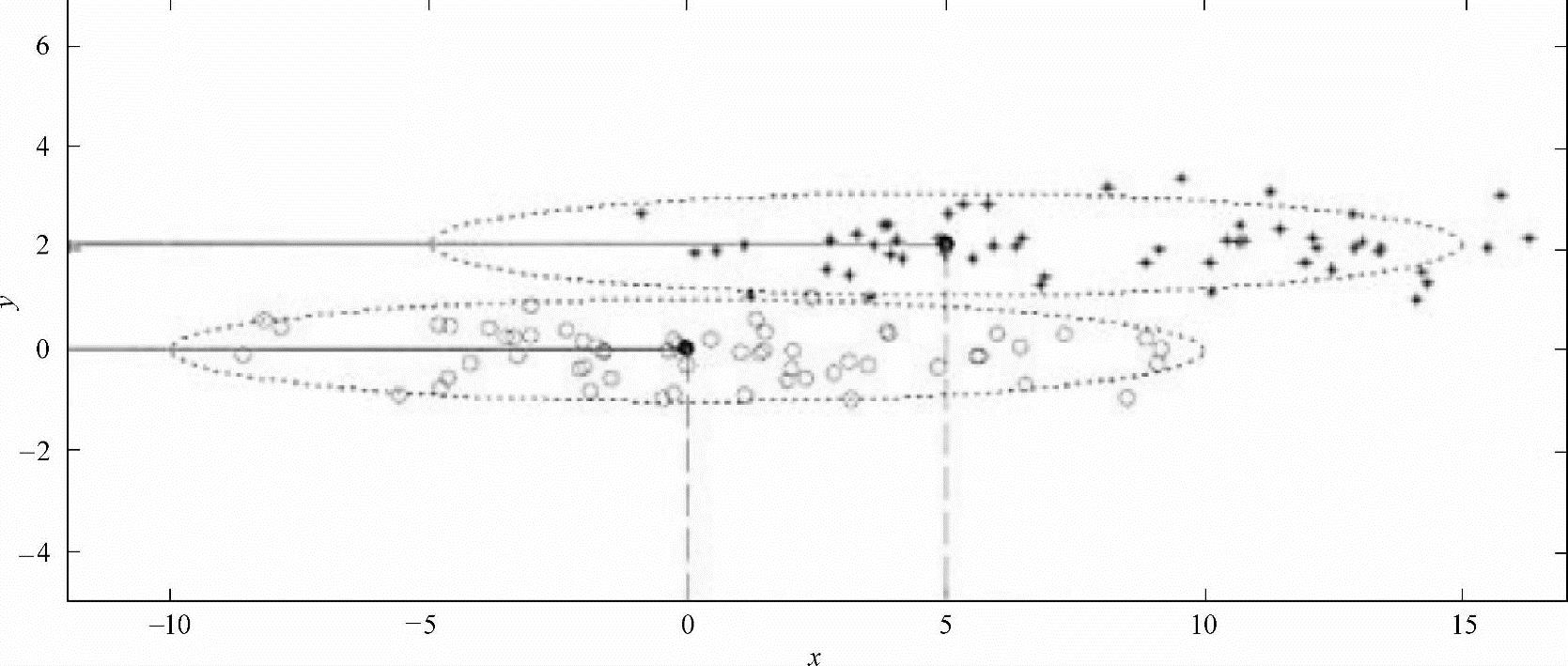
图7-1 两类数据的投影样本均值差的大小并不能完全体现两类数据的可分性
则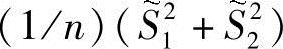 就是全部数据的投影总体方差估计,而
就是全部数据的投影总体方差估计,而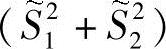 称作投影样本的总类内散布。Fisher线性可分准则要求在投影y=WTX下,要使得准则函数J(
称作投影样本的总类内散布。Fisher线性可分准则要求在投影y=WTX下,要使得准则函数J(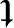 )最大化,Fisher准则函数为
)最大化,Fisher准则函数为

为了把准则函数J( )写成W的表达式,定义了类内散布矩阵Si和总类内散布矩阵SW。
)写成W的表达式,定义了类内散布矩阵Si和总类内散布矩阵SW。
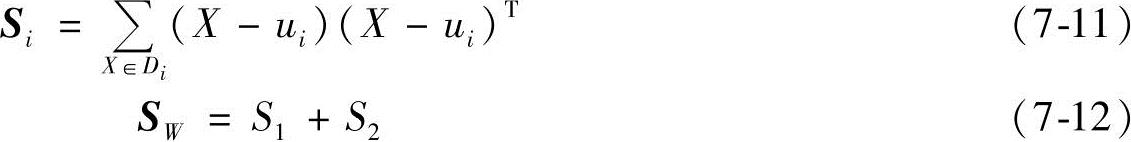
由式(7-5)、式(7-7)和式(7-9)可得
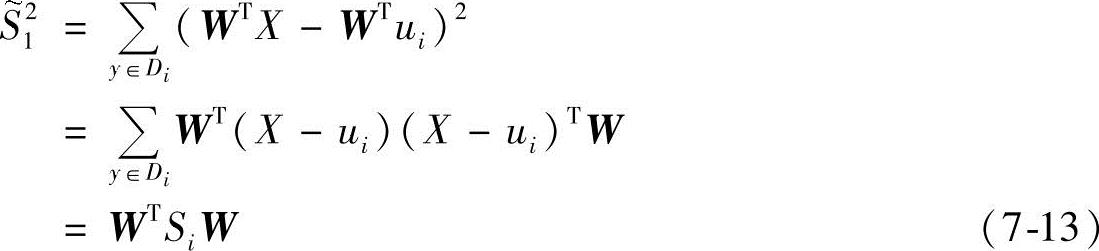
则总类内散布样本均值之差可以展开为

类似地,投影样本均值之差可以展开为
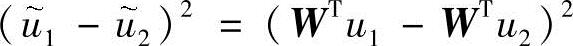
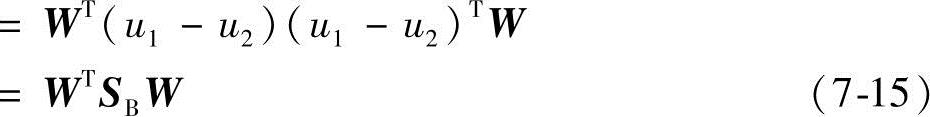
其中
SB=(u1-u2)(u1-u2)T (7-16)(https://www.xing528.com)
总类内散布矩阵SW与全部样本的样本协方差矩阵成正比,并且是对称和半正定的。当n>d时,SW通常非奇异。SB被称为是总类间散布矩阵,也是对称半正定的。此时,准则函数J(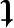 )可以写成
)可以写成

这个表达式在数学物理中是经常使用的,通常被称为广义的瑞利商。容易证明,使得准则函数J(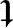 )最大化的W必须满足
)最大化的W必须满足
SBW=λiSWW (7-18)
如果SW是非奇异的,就能得到
SW -1SBW=λW (7-19)
此时,不需要真正地计算出SW-1SB的特征值和特征向量,因为SBW总是位于(u1-u2)的方向上,因此准则函数J(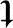 )最大时,有
)最大时,有
W=SW-1(u1-u2) (7-20)
这个Fisher可分性判据下的W就是使得类间散布和类内散布的比值达到最大的线性函数。
这样,问题就由一个d维问题转化为一维问题。此外,真正实现分类还需要一个阈值准则来获得最终的分类器,即如何确定阈值ω0,该阈值就是在一维空间中把两类分开的那个点。当条件概率密度函数P(x|ωi)是多元正态函数,且各个类别的协方差矩阵Σ相同时,可以直接计算这个阈值,此时最优判决准则就是当Fisher线性判别超过阈值时,就判为属于类别ω1,否则就判为属于类别ω2。
2.多类问题
将两类问题的Fisher线性分析加以推广,就可以得到多类问题的Fisher线性分析。
对于c类问题,就需要c-1个判别函数。也就是说,从d维空间向c-1维空间投影,且假设d>c。
设在n维空间Rn中给定N个样本x11,…,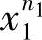 ,…,
,…,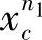 ,…,
,…,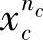 ,它们分别来自c个不同的类别,其中xji表示第i类的第j个样本,
,它们分别来自c个不同的类别,其中xji表示第i类的第j个样本,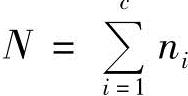 ,为了衡量数据分开的程度,定义样本的类内散布矩阵SW和类间散布矩阵SB如下:
,为了衡量数据分开的程度,定义样本的类内散布矩阵SW和类间散布矩阵SB如下:
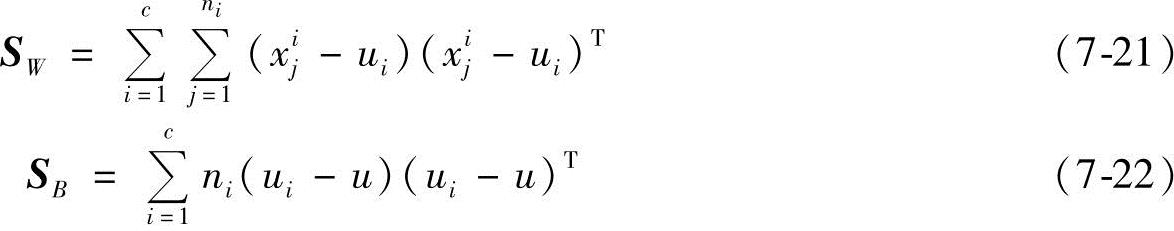
式中,c为类别数;ni为ci类的样本数;ui为ci类样本的均值,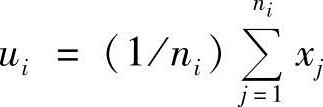 ;u为所有样本的均值,
;u为所有样本的均值,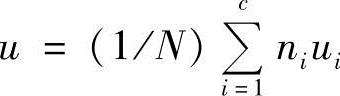 ;xji为ci类中的第j个样本。
;xji为ci类中的第j个样本。
从d维空间向c-1维空间投影是通过下面的c-1个分类方程来进行的:
yi=WTiXi=1,…,c-1 (7-23)
x1,…,xN投影后得到了新的样本y1,…,yN,这些新的样本又有自己的均值向量和散布矩阵,定义如下:
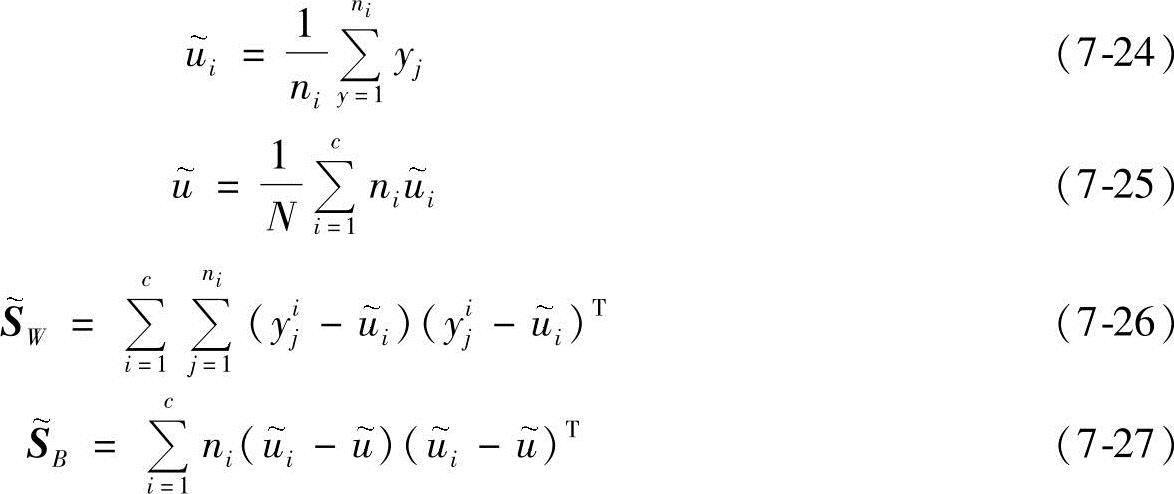
则有

我们的目的是寻找一个矩阵W,使得在某种意义上,类间离散度和类内离散度的比值最大。离散度的一种简单的标量度量是散布矩阵的行列式的值。使用这样的度量方法,得到了如下的Fisher准则函数定义为
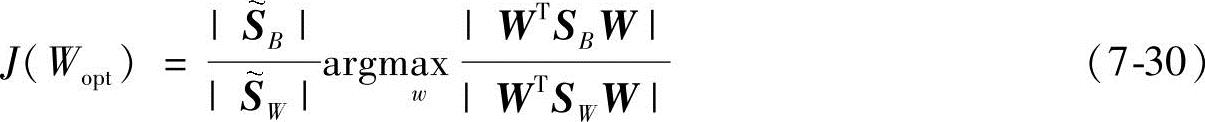
当Fisher准则函数取得最大值时,Wopt=[W1,W2,…,Wc-1]就是使类间离散度和类内离散度的比值最大的最优投影方向。通过求解下面广义特征方程的特征值问题就可以求出最优投影方向,[W1,W2,…,Wc-1]即广义特征方程的前c-1个最大特征值所对应的特征向量,即
SBWi=λiSWWii=1,2,…,c-1 (7-31)
上式在SW可逆时,即为
SW -1SBWi=λWii=1,2,…,c-1 (7-32)
求出特征向量[W1,W2,…,Wc-1]后,就可确定式(7-23)中的c-1个判别函数,由式(7-1)可知,对于所有的i≠j有yi(X)>yj(X),则把X归为ωi类。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。