



MPEG-1(ISO/IEC 11172)标准由系统、视频和音频三部分组成。它的全称为“适用于1.5Mbit/s以下的数字存储媒体的运动图像及伴音编码”。数字音频压缩编码部分为MPEG-1 Au-dio,ISO/IEC 11172-3。
为了能在同一张CD规格的光盘上同步储存数字音、视频节目,MPEG-1除了对数字视频信号进行有效压缩外,同时也规定了对数字音频信号进行有效压缩。
声音压缩编码技术的目标是将取样频率为48kHz/44.1kHz/32kHz、量化等级为16bit,数字音频的数据率压缩到192kbit/s以下,解压缩后的音质与原来的音质接近(如CD)。
声音信号的压缩是根据人耳的听感特性和听觉生理学模型,剔除信号中的冗余信息。即把20Hz~20kHz整个可闻频带按1/3倍频程的规格分割为32个子频带,把输入信号中听觉不敏感的子频带用较少的量化比特数量化,以便舍去一些次要信息;而对人耳听觉较敏感的子频带,采用较大的量化比特数量化,用较多的比特传输。此外,根据听觉生理学的掩蔽效应,对信号振幅也进行了划分,对大振幅信号之后附近的小振幅信号予以剔除(因为如果不剔除,人耳也是察觉不到这些小振幅信号的声音)。通过这些压缩方法,可获得1∶6的压缩比,将原来1.5Mbit/s的PCM声音数据压缩到300kbit/s以下。图3-8是PCM数字音频压缩编码原理框图。图3-9是MPEG-1音频编码器的基本结构。
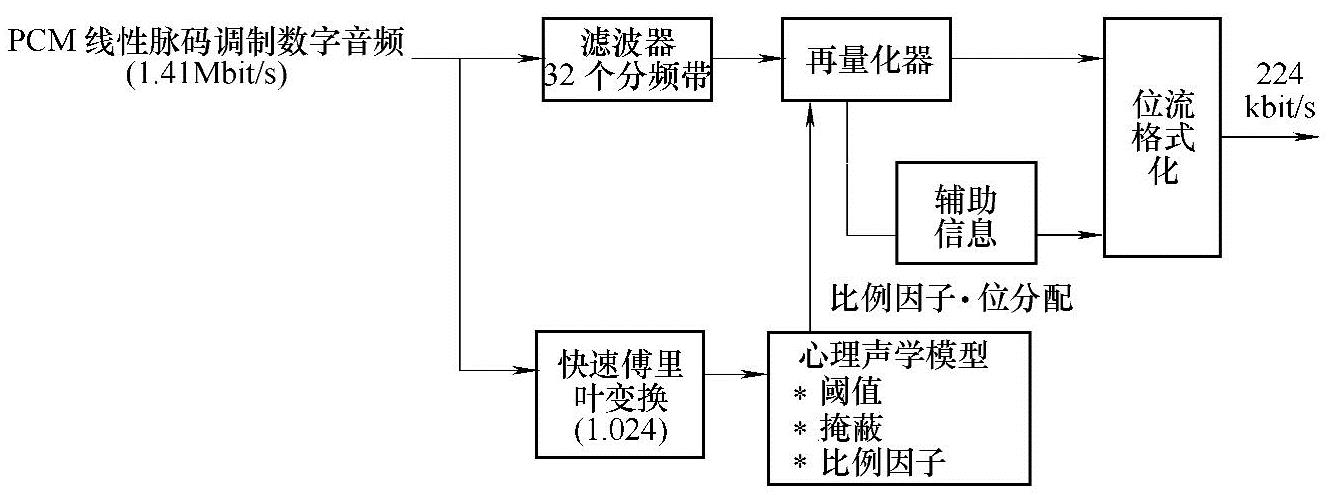
图3-8 PCM数字音频压缩编码原理框图
为了取得良好的数字音频压缩效果,MPEG-1标准充分利用了人类的听觉生理学和心理学的特性,在MPEG-1音频解码器中包含了一个心理声学模型(Psychoacoustic Model)。它的基本原理是利用人的听觉阈值特性和听觉的掩蔽特性,把压缩编码带来的失真控制在听觉阈值之下,使人耳察觉不到失真的存在。听觉的阈值特性是指听觉对不同频率的声音有不同的灵敏度,这种特性可用频率-声压级坐标中的听觉阈值曲线定量表示出来。听觉的掩蔽特性(即哈斯效应)是指两个相近频率的声音信号,声压级高的声音会掩蔽声压级低的声音,先到达的声音会掩蔽后到达的声音等。
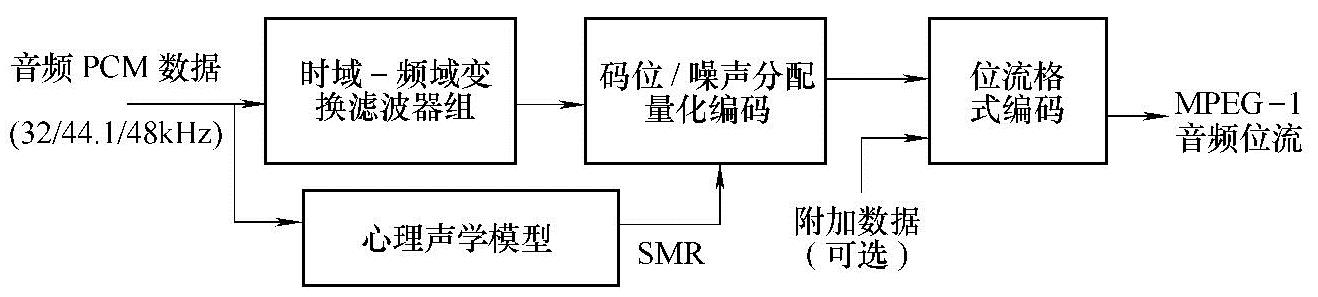
图3-9 MPEG-1音频编码器的基本结构(https://www.xing528.com)
根据不同应用的需要,MPEG-1数字音频压缩编码又引入了“层(Layer)”的概念。根据不同用途,可采用不同层面的数字音频压缩编码系统,层面越高,音质越好,但编解码器也越复杂。各层采用的编码算法如下:
层Ⅰ(Layer Ⅰ):包含把数字音频的输入分解成32个子频带的基本映射,将数据按一定格式分块,确定自适应比特分配的心理声学模型,用块压缩/扩展(Block Companding)以及格式化的量化等技术。
层Ⅱ(Layer Ⅱ):提供量化比特的分配、比例因子、采样值的附加编码和差帧(Different Framing)技术等。
层Ⅲ(Layer Ⅲ):提高混合滤波器组的频率分辨率、增加非均匀量化器、自适应分割子带以及对量化值的熵编码等。MP3就是采用了Layer Ⅲ的音频压缩编码技术。
立体声编码可作为一个附加特征添加到任何一个层中。表3-2是MPEG-1音频编码的主要性能指标,音质效果可达到CD机标准。
表3-2 MPEG-1音频编码的主要性能指标
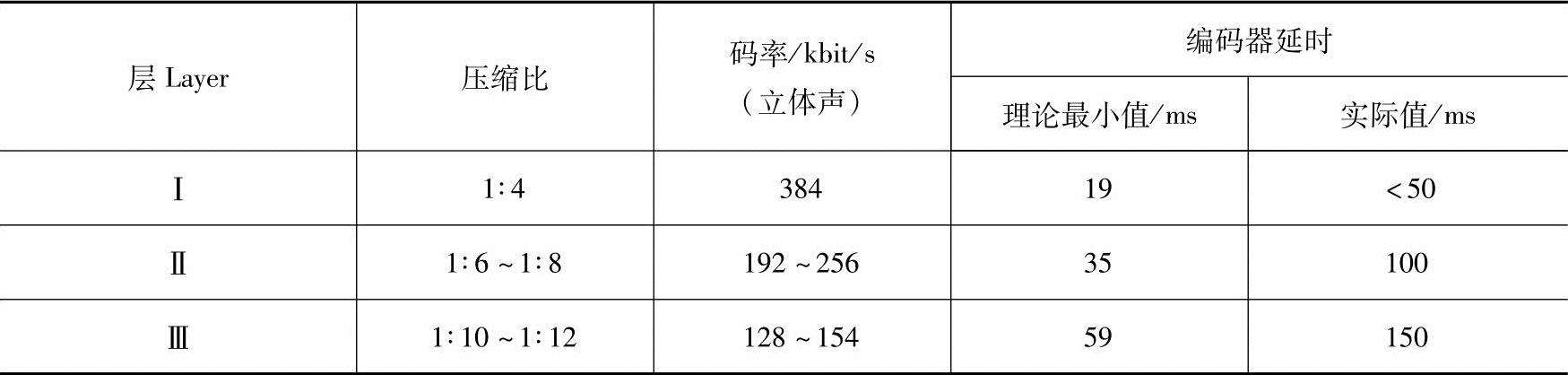
图3-10是MPEG-1音频(层Ⅰ和层Ⅱ)编码器的编码流程;图3-11是MPEG-1音频解码器的基本结构;图3-12是MPEG-1音频层Ⅰ和Ⅱ附加联合立体声的编解码流程图。附加联合立体声是一种声音强度立体声,它不是传输分离的左、右声道的子带样本,而是传送信号的和,但要附带上左右声道的比例因子,这样仍可保持重放声场的正确声像位置。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。