



(一)系统误差
1.特点
(1)对分析结果的影响比较恒定;
(2)在同一条件下,重复测定,重复出现;
(3)影响准确度,不影响精密度;
(4)可以消除。
2.产生的原因
(1)方法误差 选择的方法不够完善。
例:滴定分析中指示剂选择不当;比色分析中干扰显色的杂质的清除或掩蔽方法不当。
(2)仪器误差 仪器本身的缺陷。
例:天平不准确又未校正;滴定管、容量瓶刻度精度不高,刻度存在误差又没校正;仪器仪表指示数据不准确又未校准;色谱柱中原存的污染物未被彻底清除等。
(3)试剂误差 所用试剂有杂质。
例:去离子水不合格;试剂纯度不够(含待测组分或干扰离子);标准溶液标定后被污染,但又未发现等。
(4)主观误差 操作人员主观因素造成。
例:对指示剂颜色辨别偏深或偏浅;滴定管读数习惯性偏大或偏小。
3.减免指南
(1)方法误差 采用标准方法。
(2)仪器误差 校正仪器。
(3)试剂误差 作空白、对比试验。
对比(对照)试验:用标准样品进行测定,并与标准值相比较。
空白试验:在不加试样的情况下,按照与测定试样相同的分析条件和步骤进行测定,所得结果称为空白值。从试样的测定结果中扣除空白值可消除试剂误差。
(4)主观误差 更换操作人员或通过培训纠正操作人员主观错误。
(二)偶然误差
1.特点
(1)不恒定 可大可小,可正可负。
(2)难以校正 不能通过校正或小心操作来完全消除偶然误差。
(3)服从正态分布 从统计规律来看,偶然误差的出现呈正态分布,小误差出现的几率大,大误差出现的几率小。
2.产生的原因
偶然因素,如:实验室环境温度、压力波动,偶然出现的振动,操作人员操作精度、读数准确性的正常波动等。
3.减免指南
增加平行测定的次数。测定次数较多时,偶然误差的分布符合正态分布,在进行统计加和时,有可能相互抵偿。
(三)过失误差
1.特点
(1)技术不熟练的操作者易出现过失误差。
(2)可以避免。
(3)在一组平行试验中,发生偶然过失的试验的结果数据往往离群。
2.产生原因
由于操作失误所造成的误差,如称量时样品洒落;滴定时滴定剂滴在锥形瓶外;仪器工作条件调整中无意识的出现了错误;PCR操作中出现污染等。
3.减免指南
(1)加强操作技术训练,加强责任心。
(2)操作中一旦发现某次试验出现了难以弥补的过失,停止这次试验并重做。
(3)操作中未意识到存在过失,但发现平行试验结果中有可疑值,可采用可疑值检验方法进行检验,排除偶然过失试验数据对试验结果的影响。
(一)绝对误差和相对误差
由于试验误差(特别是偶然误差)在所难免,科学实验和生产及商业检验都允许试验存在一定的误差。在综合考虑了生产或科研的要求、分析方法可能达到的精密度和准确度、样品成分的复杂程度和样品中待测成分的含量高低等因素的基础之上提出的可以接受的最大误差数值称为合理的允许误差。所以,不论误差来源如何,误差的大小是最关键的。
在分析实验中,误差的大小可用绝对误差(Ea)与相对误差(Er)两种方式表示。
绝对误差 绝对误差=测量值-真值 即Ea=X-T
相对误差 相对误差=100(测量值-真值)/真值 即Er=(Ea/T)×100%
例如,在使用常量滴定管进行一次滴定后,有三位学生分别读得消耗的滴定液为10.00、10.01和10.02mL(最后一位小数是估计值),假如真值是10.01mL,那么这批数据的个别测定误差范围计算如下:
然而,这批数据的平均测定绝对误差和平均测定相对误差均为零。这说明,仅从平均测定绝对误差和平均测定相对误差的大小,不能看出一组平行测定的精密度。为反映一组平行测定数据的精密度,需用到偏差。
(二)平均偏差与标准偏差
1.平均偏差
平均偏差又称算术平均偏差,用来表示一组数据的精密度。
平均偏差:
式中 X——某次测定数据;
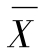 ——一组平行测定数据的平均值;
——一组平行测定数据的平均值;
n——平行测定次数。
优点:计算简单,可粗略表示一组平行测定数据的精密度;缺点:该组测定中各次测定偏差的大小差异得不到应有反映。
2.标准偏差
标准偏差又称均方根偏差。标准偏差的计算分两种情况:
(1)当测定次数趋于无穷大时 标准偏差:
式中 μ——无限多次测定的平均值(总体平均值)。
即: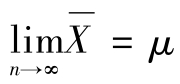 。当消除系统误差时,μ即为真值。
。当消除系统误差时,μ即为真值。
(2)当有限测定次数时 标准偏差:
相对标准偏差(变异系数):
从数学上看,标准偏差的大小既决定于各次测定是否存在偏差,又决定于各次测定偏差之间的大小差异,大的偏差比小的偏差对标准偏差影响更大。因此,用标准偏差比用平均偏差表示测定偏差更科学、更准确。
例如,对下列两组平行测定数据,分别计算出平均偏差和标准偏差比较。
可见:d1=d2,而:S1>S2(https://www.xing528.com)
3.平均值的标准偏差
若m个n次平行测定的平均值为: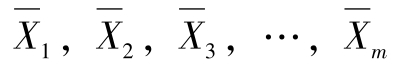
由统计学可得上列m个数据的标准偏差(平均值的标准偏差)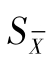 与n次平行测定的标准偏差S之间的关系:
与n次平行测定的标准偏差S之间的关系: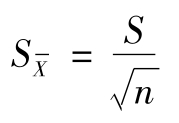
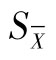 又称为标准误,它在表示分析结果时用到。
又称为标准误,它在表示分析结果时用到。
图1-3 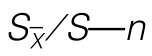 关系曲线
关系曲线
由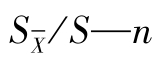 关系曲线(如图1-3所示)可知:
关系曲线(如图1-3所示)可知:
当n大于5以后,曲线变化趋缓;当n大于10以后,曲线变化不大。所以n大于5时,可以用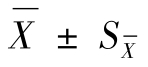 的形式来表示分析结果。
的形式来表示分析结果。
例:水垢中Fe2O3的质量分数6次测定数据为:79.58%,79.45%,79.47%,79.50%,79.62%,79.38%。计算得出:
则分析结果为:水垢中Fe2O3的质量分数=79.50%±0.04%
根据置信度和置信区间知识,用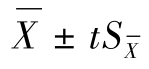 表示的结果更合理、更科学。因为用这种方式表示的结果是在一定置信度下真值所处的范围(无系统误差时)。
表示的结果更合理、更科学。因为用这种方式表示的结果是在一定置信度下真值所处的范围(无系统误差时)。
4.不确定度
不确定度表示由于测量误差的存在而对被测量值不能肯定的程度。此参数表明测量结果的分散程度,是一个正数,它反映了测量结果中未能确定的量值的范围。不确定度按误差性质可分为随机不确定度和系统不确定度,一种性质的不确定度也可由不同分量组成。不确定度的估计方法可分成两类:用统计方法对多次重复测量结果计算出的标准偏差为A类标准不确定度,以uA表示,用其他方法估计出的近似“标准偏差”为B类标准不确定度,以uB表示。用合成方差的方法将各分量合成所得的结果称为合成不确定度(例如将不同标准不确定度各分量用这种方法合成后的结果称标准不确定度,以u表示),合成不确定度乘以某一合理的正数后称为扩展不确定度(又称总不确定度,以U表示)。不确定度具有概率的概念,标准不确定度的置信概率为68.27%(按正态分布概率计算),而总不确定度的置信程度应该与之相等或更高。若需要更高,则应乘一因子(称为置信因子),这正是由合成不确定度计算总不确定度时应该所乘的那个正数。从而得出总不确定度,此时所乘的置信因子通常必须说明。
A类不确定度的计算方法如下:
对于一次进行的n个平行测定的结果,如果已排除了系统误差,规定用标准误来表征A类标准不确定度分量的数值。
当n足够大时,每一测定结果出现的概率服从正态分布,A类不确定度的置信概率为68.3%,uA就以标准误表示:
当n只是个位数时(平行测定个数只有几个时),每一测定结果出现的概率服从t分布,A类不确定度的置信概率为68.3%,uA就以下式表示:
式中 t——置信因子,在这里被称作校正系数,可根据n和要求的显著性因子在t分布表中查出该值。对于常规分析,在查该值时,通常采用置信概率P=95%或显著性因子α=0.05。
B类不确定度通常是只考虑仪器的精密度或稳定性问题引起的随机误差,其值近似为仪器测量的极限误差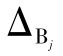 与该仪器测量随机误差的统计分布规律所对应的分布因子
与该仪器测量随机误差的统计分布规律所对应的分布因子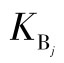 之商。
之商。
如果某次测量的平行测定个数很多,而误差的数值相差不大,可将其分布视为正态分布,一般取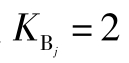 或
或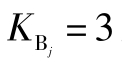 。如果某次测量的平行测定个数不多,且仪器测量时,其测量读数在一定区间基本为一个定值,那么其误差分布为均匀分布。一般取
。如果某次测量的平行测定个数不多,且仪器测量时,其测量读数在一定区间基本为一个定值,那么其误差分布为均匀分布。一般取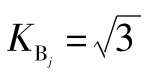 。
。
仪器测量的极限误差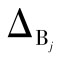 是指实验中所涉及仪器引起的最大误差,一般情况下可直接取仪器出厂检定书或仪器上注明的仪器的误差。即
是指实验中所涉及仪器引起的最大误差,一般情况下可直接取仪器出厂检定书或仪器上注明的仪器的误差。即
在各不确定度分量彼此独立情况下,合成不确定度u的计算方法如下:
设测量结果的不确定度的A分量和B分量分别独立且彼此独立,则合成不确定度为:
式中uAi——uA的第i个分量;
u B i——u B的第i个分量。
最后应当说明,在分析领域,不确定度的应用目前还不如误差的应用广泛,但在某些分析领域,它有逐渐取代误差的趋势。
(三)误差的传递
1.系统误差的传递
加减运算
Δy=Δx1+Δx2+Δx3+…
计算结果的绝对系统误差等于各个直接测量值的绝对系统误差的代数和。
乘除运算
Δy/y=Δx1/x1+Δx2/x2+Δx3/x3+…
计算结果的相对系统误差等于各个直接测量值的相对系统误差的代数和。
2.偶然误差的传递
加减运算
计算结果的方差(标准偏差平方)等于各个直接测量值方差的加和。
乘除运算
(Sy/y)2=(Sx1/x1)2+(Sx2/x2)2+(Sx3/x3)2+…
计算结果的相对标准偏差的平方,等于各个直接测量值的相对标准偏差的平方的加和。由此可见,如果要使测定结果准确性高就需要保证每次测量有较小的误差。
(四)置信度与置信区间
由于偶然误差难以完全避免,在测定获得数据后必须确定测定数据的可靠程度。
数据的可信程度与偶然误差的存在及出现的几率有着直接关系。对于不含系统误差的无数次平行测定数据,其偶然误差分布可用正态分布曲线(高斯曲线)来表征。以偶然误差(x-μ)为横坐标,偶然误差出现的频率y为纵坐标,绘制的正态分布曲线如图1-4所示。
图1-4 误差正态分布曲线
曲线的形状受总体标准偏差σ控制,σ很小时,曲线又高又窄,表明数据精密度好。
3σ的数值约等于曲线上的拐点到对称轴的距离,曲线的峰高等于1/[σ(2π)1/2]。正态分布曲线与横轴所包围面积的大小代表了误差出现的概率(可由高斯方程积分获得),如表1-1所示。
表1-1 误差出现的概率与曲线下面积的关系
由数据可见,偶然误差出现在μ±3σ范围内的概率高达99.7%。
对于不含系统误差的有限次平行测定数据,其偶然误差分布可用学生分布曲线(t分布曲线)来表征。t分布类似于正态分布,t分布曲线与正态分布曲线相似,有限次平行测定的次数n减1称为自由度f(即f=n-1),f≥5后,t分布曲线与正态分布曲线近似相等。
置信度是指人们所做判断的可靠性,或指试验所测数据的可信程度,它在数值上与平行测定所得数据中包含的偶然误差出现在一定范围的几率相等。对于有限次平行测定来说,
置信度:以测量结果的平均值为中心,在一定范围内,真值出现在该范围内的几率。
置信区间:在某一置信度下,以测量结果的平均值为中心,真值出现的范围。
置信区间可表示为:
式中 t——有限次测定结果的平均值与真值之差与有限次测定标准误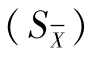 之比,在统计学中t称为置信因子,可在t分布表查出(表1-2)。
之比,在统计学中t称为置信因子,可在t分布表查出(表1-2)。
表1-2 t分布表(双侧)
从表1-2中可看出:①置信度不变时:n增加,t变小,置信区间变小;
②n不变时:置信度增加,t变大,置信区间变大。
例如,一组关于某食品的总酸含量的平行测定得到下列5个平行分析结果:1.12、1.15、1.11、1.16、1.12g/100g。求置信度为95%时该食品总酸含量总体均值的置信区间。
解: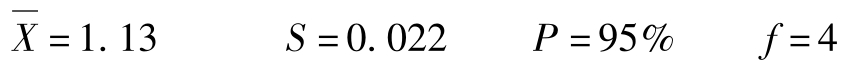
查t分布表得:
所以,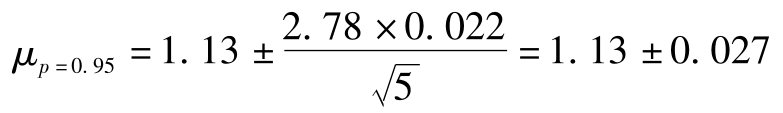
(五)在实验步骤和原始记录中控制误差
控制试验原始数据的误差是控制整个试验误差的基础。一般分析工作中,可根据试验使用的量具和仪器所能达到的最高精确度来读取和记录数据。例如,从万分之一的天平上最小可读出万分之一克,由此天平称量的物质的质量数据通常就记录到小数点后第四位。普通滴定管的刻度的最小单位是0.1mL,读数和记录的最小值应达到0.01mL,其中最后一位小数值是要求实验者通过目测得出的估计值。在做食品安全和质量检验试验时,也可按检验工作的要求来读取和记录数据。例如,检验要求称量误差、滴定误差和吸光度误差范围分别小于±1%、±1%和±2%,则用万分之一天平时被称量物的质量应不低于0.02g,用常量滴定管滴定时标准溶液的消耗量应不少于2mL,用721分光光度计时,吸光度值应控制在0.05~0.99之间。
检验工作的允许误差范围给定后,怎样来计算试验原始数据的控制范围呢?可以下面的计算为例:
如滴定管的最小刻度只精确到0.1mL,两个最小刻度间可以估读一位,则单次读数估计误差为±0.01mL。在分析中要获得一个滴定体积值V(mL),至少需两次读数,则最大读数误差为±0.02mL。若要控制滴定分析的相对误差在要求的0.1%以内,则滴定体积要大于:
V=±0.02/±0.1%=20mL
按以上要求记录原始数据的目的是将整个试验的随机误差控制在分析工作要求的范围内,并且为发现系统误差打好基础。将随机误差控制到允许的范围内后,比较现用分析方法和仪器与用精确方法和仪器的分析结果,就会发现系统误差是否存在和其大小。只有当随机误差和系统误差都控制在允许范围时才能得到满意的分析结果。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。