



1)尽量不使用select*语句,最好的办法是将要查询的字段全部列出,以提高SQL运行的效率。因为Oracle在解析的过程中,会将“*”依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间和数据库资源。
2)尽量多使用execute immediate语句,可以提高SQL执行的效率。
3)在使用游标时,如果将大量的数据集合赋给游标,运行时一般会出现内存溢出的报错信息。这时需要调整缓冲区的大小,所以使用游标时要注意内存大小的问题。
4)对于超大数据量的表应该每隔一段时间执行一次收集统计信息的操作。例如,执行dbms_stats.gather_table_stats命令,将统计信息传递给Oracle优化器,以提高数据库系统的性能。
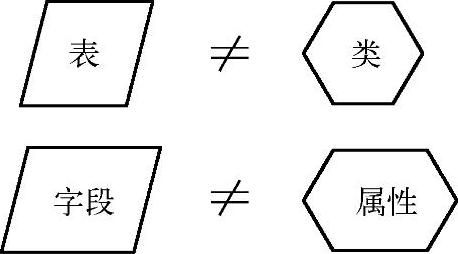
5)面向对象的最佳实践方法是为每个属性都定义一个get方法,但是不能把面向对象的实现方法应用于关系型数据库中。关系型数据库中的表不能等同于面向对象中的类,表中的字段同样不能等同于类的属性,如图2-5所示。因此查询数据库表中的字段时,应该一次性全部取出。
 (https://www.xing528.com)
(https://www.xing528.com)
图2-5 面向对象和关系型数据库的关系
6)谨慎使用自定义的函数。自定义函数通常会影响优化器对查询的优化作用。
7)检查满足某个条件的记录是否存在,绝对不要使用select count(*)语句去判断,可以考虑使用merge语句判断该记录是否存在。
总之,编写SQL代码程序的基本原则是尽可能减少数据库的连接,尽量减少表之间的关联(在表的设计过程中可以将第三范式的表转化成第二范式),少用临时表,避免将大批量的数据分割成小块的数据去处理。
此外,建议在表设计过程中尽量避免使用BLOB、CLOB等大字段,因为这样做可能会对数据库的迁移备份等造成不必要的麻烦。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。