



京津冀地区自1980年以后劳动力持续增长,从1982年的4577.82万人增长至1990年的5397.06万人和2000年的6474.63万人,在2010年达到8062.63万人。从历史数据分析可知,自1982年以来,北京城市中心区人口逐渐减少,城市外围区、近郊区、远郊区人口增速呈现由大到小排列,外围区的人口增速明显高于其他两个地区[140]。从2000年到2010年这十年间京津冀地区的劳动力空间分布变化很大。劳动力是社会经济活动的主体,劳动力分布特征反映社会经济的空间结构。
一、劳动力空间分布的衡量指标
劳动力空间分布是与一个地区的资源环境、社会经济发展密不可分的形成过程,作为生产要素的劳动力对于社会经济发展具有重要的推动作用。劳动力在空间上的集聚和扩散在一定程度上能够体现城市经济社会发展的特点。而京津冀地区地理位置紧密相连,资源、能源与产业等方面具有天然互补优势,在我国区域经济格局中占据无法替代的战略地位[141]。
本书参考人口统计学和人口地理学统计指标,结合劳动力空间分布的具体特点,选择以下指标测度劳动力的空间分布。
1.劳动力密度
劳动力密度是反映劳动力空间分布的基本指标,主要反映了劳动力分布与土地面积之间的关系,这一指标比较直观地反映了单位土地面积上劳动力的疏密程度。设某一区域劳动力数量为op,土地面积为s,劳动力密度为d,则有:d=op/s[142]。
通过劳动力密度公式可以引申出三次产业劳动力密度,其计算方法为:将式中的劳动力数换成相应产业劳动力数,不同产业劳动力密度反映的内容及其局限性与劳动力密度之相同。
2.劳动力区位熵
区位熵(Location Quotient, LQ)是经济学中一种常见的指标,主要用来识别一个地区产业集群程度。在这里主要参照产业区位熵的计算方法,构造劳动力区位熵的计算模型为:
式中:LQi—i地区劳动力区位熵;
opi—i地区劳动力数量;
pi—i地区总人口数;
op—全国劳动力数量;
p—全国总人口数。
从上述区位熵公式的算法中可以看出,这一指标主要以全国劳动力空间分布情况作为参照,反映出这一地区劳动力在空间分布的集中和分散。如果LQi>1,则劳动力在i地区相对集中;反之,LQi<1,则劳动力在i地区相对分散,不具有集中特征。劳动力密度反映了劳动力在不同区域的疏密水平,也就是说单位土地面积上劳动力的数量分布,区位熵这一指标主要表达为相对于全国人口总体空间分布而言,劳动力在这一选定区域范围内空间分布的集中与分散程度。
从上述劳动力区位熵概念公式可以延伸出三次产业劳动力区位熵公式。i地区第j(j=1,2,3)产业劳动力的区位熵值计算方法可描述为:第j(j=1,2,3)产业劳动力占i地区三次产业劳动力总和的比重,与全国第j(j=1,2,3)产业劳动力占全国三次产业劳动力比重的比值。某产业劳动力的区位熵值也是相对于全国劳动力分布来看,不同地区该产业劳动力的集中与分散,其中公式的含义与劳动力区位熵值相同。
3.劳动力人口比例
设某一地区人口总数为p,劳动年龄人口(15岁至64岁人口)数为p 15-64,劳动力为op,则劳动力比例可以由以下两个指标表示:
式中:t1—该地区劳动力总体数量占总人口的比例,它反映了总人口中参与劳动的情况,这一指标能够反映出该地区人力资源水平;
t2—三次产业劳动力占劳动年龄人口的比例,它反映了劳动力在不同产业就业情况。
4.全局莫兰(Moran)指数
为进一步识别劳动力在京津冀地区的区域分布特征,本书使用空间分析(Exploratory Spatial Data Analysis, ESDA)技术分析京津冀地区劳动力密度分布,从空间层面观察劳动力的分布特征[143]。ESDA提供对全局和局部空间自相关(Global and Local Spatial Autocorrelation)的测度,这种方法能够较为直观识别劳动力空间分布聚集与分异[144]。同时,莫兰显著性地图(Moran Significance Map)能够直观反映统计上显著的局部空间自相关及其类型。
劳动力空间分布需要用到空间自相关(Spatial Autocorrelation)分析。与时间序列相关类似,空间序列自相关理解为位置相近的区域具有类似的变量取值。设空间序列为xi,i=1,2,……,n,度量序列空间自相关的莫兰指数Moran形式为:
式中:x i或x j—空间单元i或单元j的观测值;
n—空间单元的总数;
ωij—一个二元对称权重矩阵,表示空间n个位置的相邻关系,可以根据邻接标准或距离标准来度量。这里采用简单的二进制连接矩阵,邻近关系通过0和1两个元素来表达,形式如下:
将(3-4)式中的二元对称权重矩阵行标准化(Row standardization),即将矩阵中的每个元素除以其所在行元素之和,以保证每行元素之和为1。则存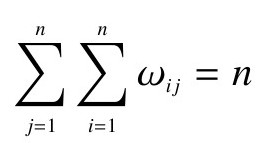 ,莫兰指数的表达式转化为:
,莫兰指数的表达式转化为:
式中:莫兰指数I∈(-1,1),若I>0,表示正相关,即为高值与高值相邻,低值与低值相邻;相反,若I<0,表示负相关,即为高值与低值相邻;若I=0,则表示空间分布是随机的,不存在空间自相关。
假设xi和x j为两个空间单元,考虑原假设H0:Cov(xi,xj)=0,i≠j不存在空间自相关。在此假设下,I的期望值和方差分别为:(https://www.xing528.com)
可以证明Z服从渐近标准正态分布,即Z→N(0,1)。选择显著性水平α,在正态分布中取临界值Nα/2,若|Z|>Nα/2则为劳动力密度的空间分布是显著相关。
5.局部空间自相关分析
全局空间自相关可反映劳动力密度的平均集聚程度,但不能回答在各区域的具体集聚状况。为了进一步搞清楚京津冀哪些地区对全局空间自相关的贡献,即各地区的空间集聚情况如何,需要进行局部空间劳动力密度的自相关分析。一般说来,局部自相关分析方法包括局部莫兰指数显著性地图、G统计量和莫兰散点图。本书采用莫兰指数散点图和莫兰指数显著性地图进行局部自相关分析。
采用局部莫兰指数,表达形式为:
莫兰指数显著性地图按局部空间自相关类型将区域单元划分为高-高、低-低、高-低、低-高四种类型。高-高或低-低是指具有较高或较低观测值的单元,其相邻区域的观测值也较高或较低,代表高值或低值的局部空间集聚,而高-低或低-高则反映局部空间分异。
二、京津冀劳动力空间分布特征
1.京津冀劳动力分布总体呈现北疏南密的态势
京津冀各地区劳动力分布具有显著的地域差异,北部、西北部山区人口密度较低,而南部、东南部平原地区人口密度较高。北部的承德、西北部的张家口、东部的秦皇岛、中南部的保定、沧州和衡水以及与之相连的北京平谷区、天津蓟州区、天津静海区和天津宁河区劳动力密度较低。环北京和天津两大都市的北京、天津周边区县和唐山地区以及河北平原地区的邯郸、邢台和石家庄地区劳动力分布密集。而从行政省份划分来看,河北省劳动力密度大的地区为石家庄、邯郸和唐山,2010年邯郸劳动力密度为552人/km2,是河北省劳动力密度最高地区,其次是省会石家庄,劳动力密度为492人/km2。劳动力密度分布最稠密的当属北京和天津两大都市,劳动力密度增长在地域上形成了两条轴线,即以北京、天津都市圈经济发展带动的中心轴和以石家庄省会为中心的冀南经济发展带。
从图3-1中可以看出,莫兰指数为正数的个数较负数多,表明各区域呈现集聚的趋势,这与全局莫兰指数为正数是相一致的。在空间上看,北京市各区县的莫兰指数基本为正数,表明北京市各地区空间集聚较为明显;而天津市各区县的莫兰指数基本为负数,表明天津市各地区空间分异较为明显;河北省各地区存的莫兰指数有正有负,其中秦皇岛市和承德市三年均为正数,沧州的莫兰指数为负数。
图3-1 京津冀各地区的莫兰指数
2.京津冀劳动力分布不均衡格局长期稳定,呈现双核三轴特征
从1990年、2000年和2010年局部相关性检验结果可知,显著性地图差异较小,这表明京津冀劳动力密度分布格局相对稳定。局部空间自相关显著的区域主要是以高-高、低-低和高-低为主。从横向看:显著性的高-高类型主要集中在北京市区、近郊区,显著性的高-低类型主要集中在天津市区、近郊区,显著性低-低类型主要集中在承德与北京市的密云、怀柔等区县连片的山丘区,形成了劳动力密度的低值区。张家口、秦皇岛、唐山、保定、沧州、衡水、邯郸、香河、廊坊、天津宝坻和北京昌平空间相关性不显著。从纵向看:以北京市为中心的集聚区,在2000年以前空间集聚表现不很明显,而在2010年形成了与通州、大兴为都市群的高度集聚区,且通过α=0.05的显著性检验,这与北京市分别在1997年、2001年实施县改区,加快城区建设,实现城区一体化是相一致的。
结合京津冀劳动力密度,计算整个研究区的全局莫兰指数,结果见表3-1。
表3-1 莫兰指数计算结果表
从表3-1中可以看出,各年的莫兰指数均为正值,表明京津冀劳动力空间集聚,在1990年和2000年的劳动力空间集聚表现不明显,而在2010年劳动力集聚呈现跃增现象。
劳动力分布形成“双核三轴”的空间格局。“双核”是指北京、天津,1990-2010年劳动力在北京和天津两大都市最为密集,其中北京市劳动力密度在整个区域内最高,2010年北京市劳动力密度达到2235/km2;三轴指“北京-廊坊-天津”“北京-保定-石家庄-邢台-邯郸”“秦皇岛-唐山-天津-沧州”三条劳动力分布密集轴,三条轴线连接了京津冀主要城市的城区。河北石家庄、邯郸、唐山、秦皇岛和廊坊地区与北京、天津劳动力分布形成三条轴线,劳动力以这三条轴线为骨架连线呈现空间密集分布,同时它也涵盖京津冀较为重要的产业带,因此已经初步形成以产业、交通、劳动力相互协同发展的带状区域;京津冀地区劳动力密度最低的是承德和张家口,其中承德劳动力密度低于张家口。
3.劳动力空间极化特征持续加剧
劳动力集聚与扩散能够诠释地区经济发展与产业空间结构,对劳动力空间分布的研究有助于理解这一区域的空间结构特征,同时判断区域经济发展阶段[145,146],从而实现劳动力的优化合理配置,缩小地区差距推动区域经济发展。
京津冀地区分布格局表现为北京地区劳动力增加速度快,天津和河北地区增加较为稳定。从1982-2010年京津冀人口普查数据计算可知,北京、天津的劳动力密度增加迅速,1982年,北京、天津的劳动力密度分别为323人/km2、370人/km2,到2010年,北京劳动力密度为671人/km2,天津为530人/km2,可以看出,京津两地劳动力密度大幅增加,同时,北京每平方公里劳动力比天津多141人。河北劳动力密度基本保持稳定增加,1982年为146人/km2,2000年为202人/km2,2010年劳动力密度为217人/km2。在北京和天津劳动力密度显著变化的十年里,河北的劳动力密度基本保持不变。
为描述京津冀各地区劳动力密度的空间相邻关系,采用莫兰散点图表示(图3-2~图3-4)。
图3-2 1990京津冀劳动力密度空间分布莫兰散点图
图3-3 2000京津冀劳动力密度空间分布莫兰散点图
图3-4 2010京津冀劳动力密度空间分布莫兰散点图
其中wy表示区域的空间滞后,即为某区域y邻居的平均值。图中的任意一点,横坐标为该区域的莫兰指数,纵坐标为该区域的空间滞后。描述了该区域与周围区域的关系,点到线性拟合线的距离大小表示该点代表的地区与其他地区劳动力密度的差异程度。点位居第一和第三象限表示该区域在空间聚集,即高-高值和低-低值;居于第二象限表示该区域在空间分异,即高-低值和低-高值;若点离原点越近,表示相邻区域之间不存在相关。
从图3-2~图3-4中可以看出,大部分区域位于第一、第三象限,结果与京津冀劳动力密度呈现正相关,与全局莫兰指数为正数是一致的。在上述的三个图中,均存在27个点中均有6个点分布在第二和第四象限内。与2000年相比,2010年和1990年远离趋势线,表明京津冀各区域劳动力密度的差距在拉大,区域劳动力分布不平衡,存在空间局部聚集趋势。
4.京津冀各区域劳动力增幅不一
从1990-2000年的10年间,北京和天津的各区县增幅较慢,河北省一些地区劳动力增幅很快,比如邢台2000年的劳动力密度在1990年的基础上增加了7.3倍。同时,北京劳动力密度增加值很大,1990-2000年每平方公里新增劳动力数为428人。天津市区的劳动力密度一直在持续增加,但增加速度较为温和,每平方公里新增劳动力数为221人;在2000-2010年的10年间,京津地区劳动力数变得集中密集,新增劳动力数较1990-2000年十年间增加迅猛。北京每平方公里新增劳动力数为642人,其中位于北京周边的大兴、通州和昌平在2000年后劳动力数增加异常迅速,昌平、大兴和通州这些紧邻北京市的区域,随着由县改区和城市交通网的建设,北京市经济的辐射和带动作用,吸纳了大量的劳动力,在2010年劳动力密度均突破1000人/km2。通过两组数据对比可见,1990-2000年,北京大兴区、通州区和昌平区每平方公里新增劳动力数为138人、98人和132人,而在2000-2010年10年间这三个地方的每平方公里新增劳动力数为625人、527人和690人,尤其昌平区在10年间增加了1.89倍。但天津在2000年后增加迅速,2000-2010年10年间每平方公里新增劳动力数648人,每平方公里新增劳动力数与北京基本一致,但天津周边县劳动力新增劳动力数比较平缓,没有很大的变化。在这一时期河北各地区的劳动力密度增幅平缓。
从1990-2010年这20年来看,年均增幅超过10%的为邢台、沧州和保定地区,剩余的年均超过5%的为邯郸、石家庄、承德、张家口、北京市大兴区和昌平区,增幅最慢的为北京密云区和天津蓟州区,不足1.05%。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。