



四、最大差异选择[27]
(一)选择第二人
从第二人开始,如果不挑选对象,只要访谈的人足够多,最终也能实现信息饱和。为了更加迅速地实现这一目标,应该选择拥有的信息与第一人存在最大差异的那些人作为我们访谈的第二人。但是在访谈之前我们很难知道谁拥有这样的信息,因此只能根据对方最显而易见的社会特征,来选择与第一人差异最大甚至截然相反的人作为第二人,例如性别、年龄、城乡差别、风度举止等。即使某些相对隐蔽的社会特征(受教育程度、婚姻状况、职业等)也可以通过只言片语的询问而获知。
研究者可以依据自己的研究目标,挑选出一些最相关的社会特征列出交叉表,根据最大差异法,选择第二人。例如,在笔者主要从事的“性”研究中,笔者就是依据表8—1所示的社会特征来选择第二人的。
表8—1 相关社会特征交叉图
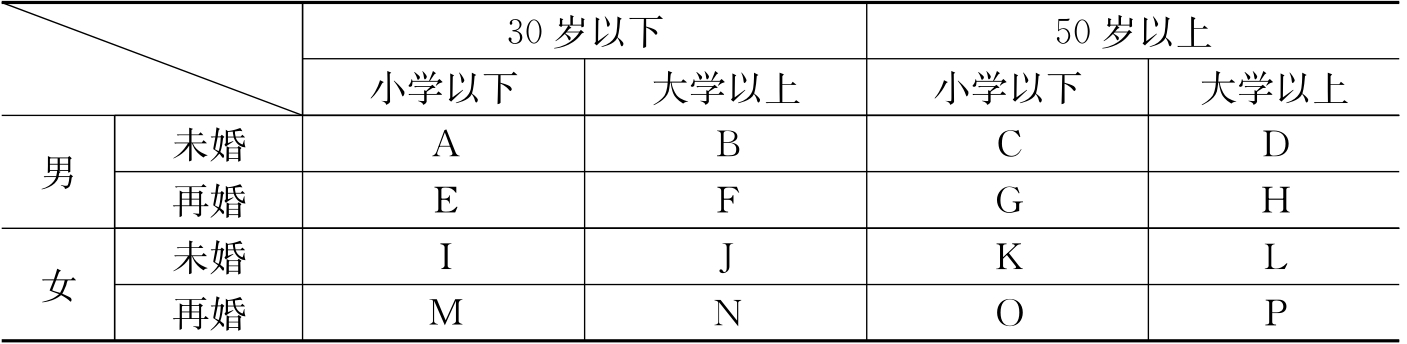
假设笔者选择的第一人是A,那么第二人就应该选择P。依据性别、年龄、受教育程度、婚姻状况四种社会特征来看,P和A之间存在最大差异。笔者预期可以从第二人那里获得最大差异的信息。
(二)选择第三人与后续对象
在访谈过第二人并且梳理所获得的信息之后,会出现三种情况。
第一种情况是,第一人(A)与第二人(P)的信息并不存在显著的差异。这说明我们据以选择第二人的社会特征的假设不能成立,那么我们就必须提出一些新的社会特征来重新建构一个新的交叉表,然后仍然按照最大差异法来选择第三人。
例如,在笔者从事的“性”研究中,确实出现过这种情况。在第一调查地点,两位年龄、受教育程度、婚姻状况都截然相反的“男客”(嫖客)却对“嫖”这一行为给出了大同小异的解释与期望。笔者只好在第二调查地点另辟蹊径,加入城乡差别这一新的维度,去访谈进城打工的农民。结果不但真的获得了新的信息,而且受到启发,在第三调查地点再次把社会特征的维度修改为“是否退休”,所以仍然获得了新信息(潘绥铭等,2008)。
第二种情况是,A与P的信息确实存在有意义的差异。此时我们就应该梳理清楚两个人的信息究竟主要来自哪些社会特征的影响,然后按照这一发现所指出的方向在原有的交叉表里选择差异最大的第三人。
例如,笔者在上述的“性研究”中曾经发现具有类似年龄、职业与受教育程度的两位“男客”对于“嫖”的意义的理解却存在很大的差异,造成这种差异的主要原因是两个人的妻子的管束程度很不同。因此,笔者就从婚姻状况的角度去选择第三人,应该是D。也就是暂时忽略那些作用甚微的社会特征(年龄、职业与受教育程度),专门选择婚姻状况这一个维度上的最大差异。
第三种情况是,A与P之间的信息差异并不是来自某个单一的社会特征,而是两种或者更多的社会因素在发挥作用,那么就需要按照交叉的方向来选择。[28]以上述的交叉表为例,如果年龄与性别的作用都很小,那么P之后的第三人就应该选择K或者O。如果再加上受教育程度的作用也很小,则可以选择J或者N。如果上述交叉表所列出的四种社会特征都没有对信息的差异发挥显著作用,那么这就属于前述第一种情况了,就应该重新建构交叉表了。
从选择第三人往后,都是依此类推,直到信息饱和。
(三)第一人的再选择
在定性调查实践中会遇到这样的情况:按照一般程序开始访谈,但是在访谈第二人甚至第一人时就遇到被访者“言表缺失”的情况(没的可说或者说不出来),而调查者却觉得收集到的信息仍然不足以进行分析。这种情况在低阶层人口或者边缘人群中屡见不鲜,因为他们往往缺乏对于自己的生活进行总结、思考和表达的各种能力。[29]
遇到这种情况就需要我们依据极其有限的资料(往往仅仅是观察结果)来进行判断。如果这种“言表缺失”的情况在某人群中很普遍,那么我们就必须放弃访谈调查的方法,改用参与观察等其他方法。如果只是我们“选人不当”,那么上述的最大差异选择的社会特征交叉表就可以派上用场了。我们可以根据与原来第一人的最大差异,再次选择另外的新的第一人,重新开始新一轮的访谈。
(四)最大差异法与定量调查中的比例分配抽样的不同性质(https://www.xing528.com)
其一,最大差异选择绝对不是要调查完从A到P的所有人,更不考虑各种人所占的比例。如果幸运的话,那么访谈完第一人就有可能实现信息饱和,而且对于该次定性访谈的质量与价值毫无损害。
其二,最大差异选择也不是要反映各种社会特征的现状或者作用,而是假设社会特征的差异可能带来信息的差异,而且随时准备否定这一假设。
其三,最大差异选择不但允许而且主张因人而异地随时转向,全面重构。
总而言之,如果非要使用“唯科学主义”的思维定式与话语来表述的话,那么定性调查的命根子是“相关的潜在信息”这样一个“总体”,而最大差异选择则是获取它的最佳方式。反之,定量调查的总体是可以计数的人头,但是从获得新信息这个角度来看,这些“样本”基本上都是“废物”,因为他们在回答问卷的时候不可能主动提供新的信息,而且问卷调查的设计者往往也不需要甚至不允许调查员去记录这样的新信息。因此定量调查的随机抽样结果所具有的代表性,其实只是既有信息的分布状况,而基本没有任何新信息。即使是进行统计学的相关分析,所获得也只是既有现象之间的关系,却无法发现新的现象。由此,两种调查方法的质的差别,一目了然。
(五)最大差异选择的方法论意义
最大差异选择法的基本原理有三个。
1.人是分层的
人是按照差异性来分层地存在的,这是社会学的基本共识。虽然我们在调查之初无法知道,就我们的调查目标而言,第二人与第一人之间所存在的一般意义上的社会差异究竟会不会造成两者所拥有的信息的差异,但是寻求具有最大差异性的信息确实是实现信息饱和的终南捷径,这样做毕竟比再找一个基本相似的人来调查要有根据得多。
2.信息是光谱式存在的
这个命题与本节有关的意思有三层。
其一,信息的存在方式。就像人类可见的光谱存在左右两个极端的边界一样,信息也存在边界;就像光谱的左界外是不可见的紫外线,右界外是同样不可见的红外线那样,人类可知的范畴也是有限的。这就是我们可以用社会调查来了解到的信息饱和的界限。
其二,光谱无法被定量地精确分类。任何一种分类方法都是人为定义之后对于光谱的生硬切割,必然存在逻辑上的疑问:与该分类的距离微乎其微的那个色彩为什么就不属于该分类呢?生活中的具体例子是,如果37.5摄氏度算发烧,那么为什么37.499 99度就不算呢?
其三,由于光谱(信息)无法被定量分类,因此也就无法被抽样,无论这种抽样是不是随机的。但是它又确实是一个存在着的总体,因此必然有某种方法可以实现对于该总体的代表性,而且这种方法一定不同于定量调查中的各种抽样方法。
3.从一点走向两个极端,最容易最大限度地涵盖光谱
光谱虽然无法定量分类,却有不同的主色,例如被命名为“黄色”的那个色彩区域,我们虽然无法断定其边界,但是“黄”毕竟存在。这就是质性意义上的“类”。因此笔者主张选择信息最丰富的人作为第一被访者,就相当于在最接近自己研究目标的主色上首先切入光谱。其价值不言自明。
为了最大限度地包括最多的主色,最佳的方法是从切入点直接走向光谱某一个方向的边界,然后再反过来走向它的最大差异点,也就是另外一个边界。正是由于我们不大可能仅仅走这么两次就到达两个极端,我们每次都只是在接近极端,所以只要每次选择都贯彻最大差异原则,那么就等于在不断靠近两个极端的一些不同的主色之间往返,其结果就是到达了尽可能多的色彩区域,最终贴近了光谱的“囊括”,信息也就相对饱和了。
当然,与定量调查不同,这里的“囊括”不等于也根本不应该等于“涵盖”。它寻求的是尽可能地把“赤橙黄绿青蓝紫”都收纳进来,以便实现一种“类的概括与分析”[30]。尤其值得注意的是,定量调查的随机抽样抽取的是人头,而最大差异选择法囊括的却是信息的域。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。